
Ebook Translator:用 Calibre 翻译多格式双语对照电子书

- 新增功能:在审阅编辑器中添加行号和同步滚动
- 新增功能:为 Gemini 添加波斯语支持
- 新增功能:改进模型获取提示的清晰度
- 修复:修复导致配置迁移错误的错误
- 修复:修复阻止转换 PNG 和 SRT 文件的错误
- 其他错误修复和功能增强
Ebook Translator 是书伴开发的一款 Calibre 插件,可以将不同格式不同语言的电子书翻译成指定语言(原文译文对照)指定格式的电子书,支持 Google、ChatGPT 和 DeepL 翻译引擎。
在日常的生活、工作或学习中,如果在阅读或翻译外文电子书的过程中需要频繁使用翻译软件,在内容和翻译软件之间来回切换,可能会成为一件颇为痛苦的事。Ebook Translator 插件借力 Calibre 对电子书的强大处理功能和翻译引擎对多种语言的翻译支持,可以轻松将译文添加到原文段落之后,如下图那样形成双语对照,方便辅助对原文的理解或作为译制材料时的参考。

▲ Ebook Translator 插件翻译的电子书效果
借助 Calibre 对多种电子书格式的灵活支持,进行翻译时,你可以自由地选择输入输出格式,比如把 TXT 翻译成为 TXT 或 EPUB,把 PDF 翻译成 PDF 或 DOCX。
Ebook Translator 插件源代码使用 GPL v3 许可证。插件项目托管在 GitHub 上。
一、功能简介
★ Ebook Translator 插件主要包含以下功能:
- 支持“批量模式”和“高级模式”两种翻译模式,应用于不同使用场景
- 支持所选翻译引擎所支持的语言(如 Google 翻译支持 134 种)
- 支持多种翻译引擎,包括 Google 翻译、ChatGPT 以及 DeepL
- 支持自定义翻译引擎(支持解析 JSON 和 XML 格式响应)
- 支持所有 Calibre 所支持的电子书格式(输入格式 48 种,输出格式 20 种)
- 支持批量翻译电子书,每本书的翻译过程同时进行互不影响
- 支持缓存翻译内容,在请求失败或网络中断后无需重新翻译
- 提供大量自定义设置,如将翻译的电子书存到 Calibre 书库或指定位置
★ Ebook Translator 插件支持翻译的语言:
- Google 翻译支持的语言列表
- DeepL 翻译支持的语言列表
- ChatGPT 具体支持语言不详
- 有道翻译支持的语言列表
- 百度翻译支持的语言列表
★ Ebook Translator 插件支持的输入格式:
EPUB, AZW3, AZW4, MOBI, PDF, DOCX, TXT, MARKDOWN, RTF, RECIPE, HTML, HTM, XHTML, XHTM, TXTZ, CB7, ODT, RAR, FBZ, CBC, SHTM, TEXT, SHTML, POBI, UPDB, OPF, TCR, PML, PDB, CHM, SNB, LRF, LIT, RB, DOWNLOADED_RECIPE, CBR, DJV, DJVU, MD, AZW, TEXTILE, DOCM, HTMLZ, PMLZ, CBZ, ZIP, PRC, FB2,SRT,PGN
★ Ebook Translator 插件支持的输出格式:
EPUB, AZW3, MOBI, KFX, PDF, DOCX, TXT, RTF, OEB, TCR, PDB, SNB, LRF, TXTZ, LIT, RB, HTMLZ, PMLZ, ZIP, FB2,SRT,PGN
二、安装插件
首先确保你的操作系统已经安装了 Calibre,然后通过一下任意方式安装本插件:
【方法一】通过 Calibre 安装
- 打开 Calibre 并依次点击其菜单【 首选项… → 插件 → 获取新的插件 】;
- 在插件列表中选中 Ebook Translator 然后点击 【 安装 】 按钮(请留意,首次安装此插件时,要选择把图标显示在主工具栏上);
- 最后关闭并重新打开 Calibre 即可正常使用。
【方法二】通过插件文件安装
NAME: Ebook-Translator-Calibre-Plugin_v2.2.0.zip
MD5: 4eda05385bf2f49d1b8a066b9795e3ab
SHA1: e9bcfc0d02c51dc7dd7d9de9a1f4b0c12e3f6ba0
- 首先在通过以上链接下载插件文件;
- 然后打开 Calibre 并依次点击其菜单【首选项 → 插件 → 从文件加载插件】;
- 在弹出的对话框中选择下载的扩展名为 .zip 的插件文件完成安装(请留意,首次安装此插件时,要选择把图标显示在主工具栏上);
- 最后关闭并重新打开 Calibre 即可正常使用。
如果想安装最新版本,可以访问 https://translator.bookfere.com 点击按钮【Rolling Release】下载。注意,最新版本在每次提交代码时自动生成,未经过严格测试,可能会存在错误。
如果安装插件后,插件图标未出现在 Calibre 的主工具栏上,可以依次点击 Calibre 的菜单【首选项 → 工具与菜单】,在弹出的对话框中点击下拉菜单并选择“主工具栏”,然后在左栏找到并选中插件图标,点击中间的右箭头按钮【>】将其添加到右栏,最后点击【应用】按钮即可。
三、使用方法
Ebook Translator 提供了两种翻译模式,在开启缓存状态下两者共享同一缓存数据。
1、高级模式
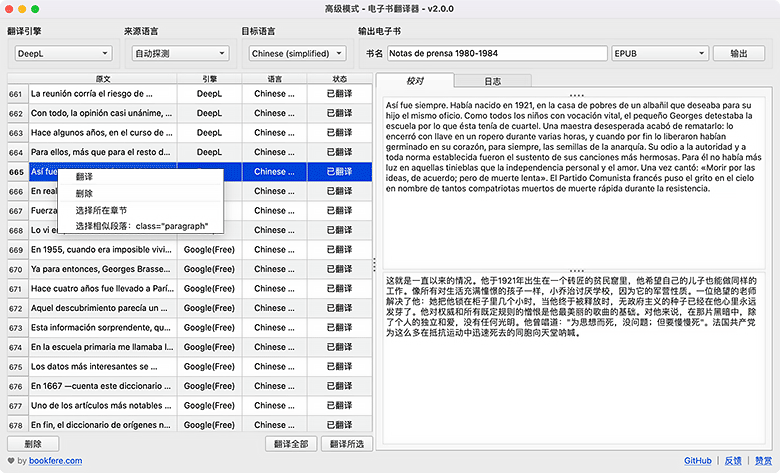
- 在 Calibre 书库中选中要推送的电子书,点击 Calibre 主工具栏上的【翻译书籍】图标按钮,或点击图标下拉菜单选择【高级模式】;
- 在弹出的提示框点击选择“高级模式”(首次打开);
- 选择“输入格式”和“输出格式”,点击【开始】进入“高级模式”翻译主界面;
- 点击【删除】按钮删除需要忽略翻译的选中段落(可选);
- 通过以下两种方式进行翻译:
- 点击【翻译所选】按钮翻译选中的段落
- 点击【翻译全部】按钮翻译全部电子书内容
- 翻译完成后,在右方“校对”区域,通过编辑下方文本并点击【保存】,可以更改翻译结果;
- 点击【输出】按钮,存储翻译完成后的电子书。输出任务将被推送添加到 Calibre 的任务队列。
2、批量模式
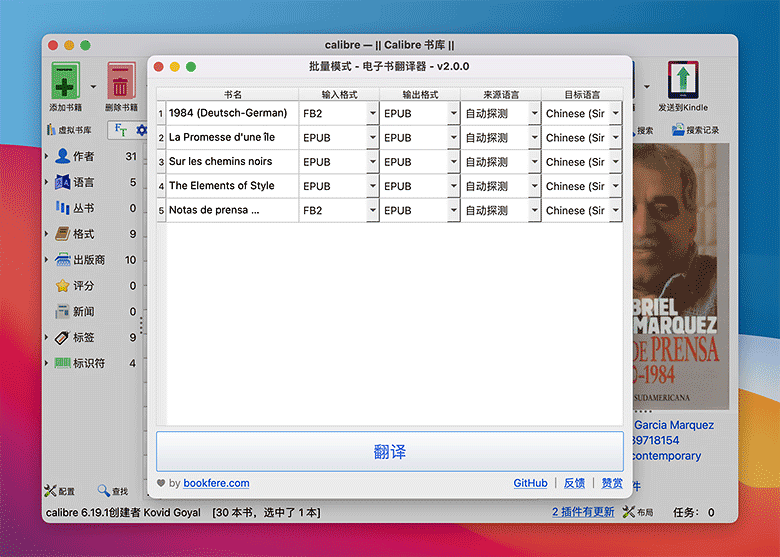
- 在 Calibre 书库中选中要推送的电子书,点击 Calibre 主工具栏上的【翻译书籍】图标按钮,或点击图标下拉菜单选择【批量模式】;
- 在弹出的提示框点击选择“批量模式”(首次打开);
- 进入插件主界面,在这里你可以修改“书名”(作为保存文件时使用的文件名),分别为每一本书选择“输入格式”、“输出格式”、“来源语言”(一般情况下“自动探测”即可满足需求)、“目标语言”(默认使用 Calibre 界面当前所用的语言);
- 点击下方的【翻译】按钮即可开始翻译。
插件会将每本电子书的翻译任务推送添加到 Calibre 的任务队列,你可以通过点击 Calibre 右下角的【任务】查看推送详情,双击任务条目可以进入日志实时查看正在翻译的内容。
三、插件设置
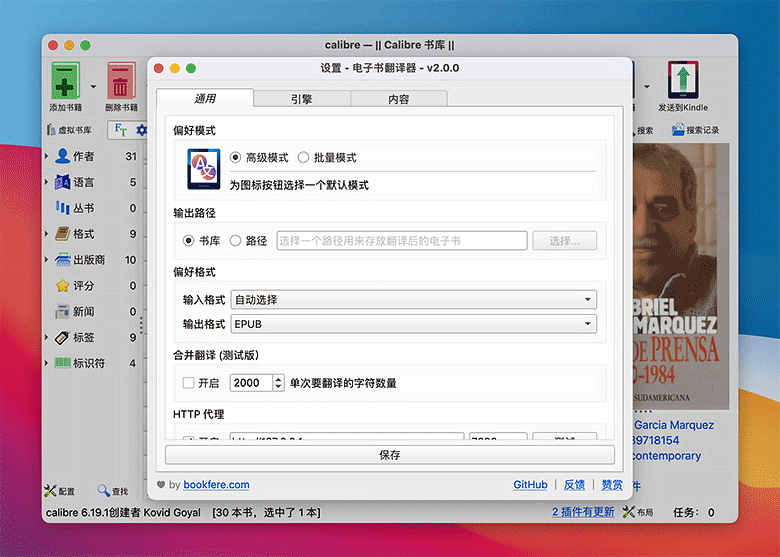
▲ Ebook Translator 通用设置
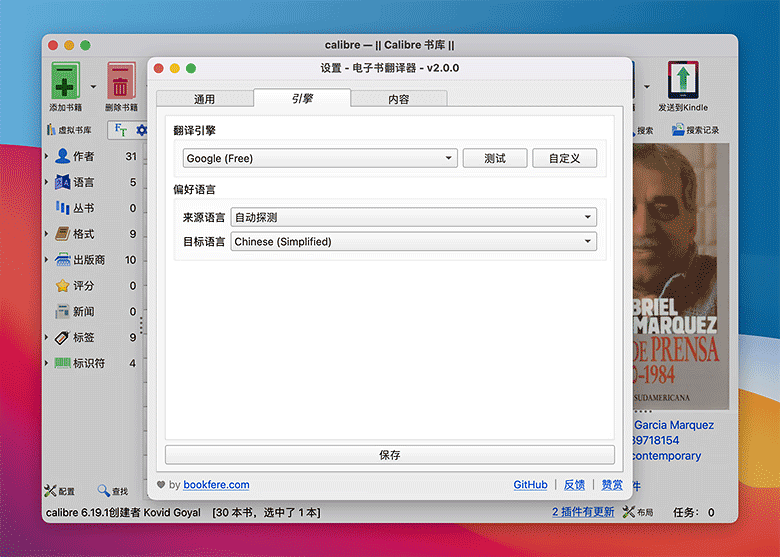
▲ Ebook Translator 引擎设置
▲ Ebook Translator 内容设置
有关设置内容的详细说明请查阅 Ebook Translator 项目的 Wiki 页面。
五、注意事项
开发 Ebook Translator 插件测试用的 Calibre 版本是 3.48 和最新版版本,因此理论上插件在 3.x 到 6.x 版本的 Calibre 中都能正常使用,但是如果版本低于 3.x,可能无法正常使用。
尽管 Ebook Translator 插件在发布会尽可能测试,但仍无法保证在任何情况下不会出现问题。
如果你在使用插件的过程中遇到了问题或有好的建议,欢迎报告错误或提交功能请求。
六、常见问题
1、翻译文件丢失
有些用户反馈翻译完成后无法打开文件,此问题通常发生在 Windows 系统上。在 Windows 系统中,有一个功能叫做 “存储感知”,它会自动清理长时间运行程序的临时文件。
为避免此问题,请通过插件的缓存管理器为缓存另外指定文件夹(请勿选择任何临时目录)。
2、翻译速度太慢
普通翻译服务(如 Google Translate)翻译 1000 个段落通常仅需不到 1 分钟的时间。如果你使用的是 ChatGPT 之类的生成式 AI,耗时则有较大的差异,建议根据服务的速率限制在设置中修改并发请求和请求间隔以加快翻译速度。另外,也可开启合并段落功能大幅提升翻译速度。
3、合并翻译效果
在使用 ChatGPT 时合并翻译功能表现较差,这是因为插件会在合并后的文本中添加标记,由于无法保证 ChatGPT 翻译这些文本后仍会保留这些标记,因此无法保证最终的翻译效果。因此,如果要使用的 ChatGPT 翻译电子书,不建议开启合并翻译功能。
© 「书伴」原创文章,转载请注明出处及原文链接:https://bookfere.com/post/1057.html
延伸阅读
- [Kindle漫画] 萌萌K小贱与傲娇纸质书的恩怨纠结
- [2019.02.15] Kindle 阅读器固件升级至 5.10.3
- [2022.01.05] Kindle 7 & KPW2 固件升级至 5.12.2.2
- Kindle Oasis 2017 详评:从硬件软件到使用体验
- 丛日云:人生多歧路,你将如何做出选择
- [每周一书]《自由选择》地球人不可不读的书
- [每周一书]《饱食穷民》泡沫经济时代的日本社会
- [2024.10.21] Kindle 阅读器固件升级至 5.17.1
- 纸质书与电子书:哪一种在保护森林和碳减排方面更出色
- 技术恐惧时代:Kindle毁了纸质书?
- [每周一书]《地理与世界霸权》地理如何影响人类历史?
- [每周一书] 经典文学《一个陌生女人的来信》
- [每周一书] 读《黄帝内经》重新发现中医太美
- 2017 年亚马逊会发布 Kindle Paperwhite 4 吗?
- 亚马逊是否真的会推出带彩色屏幕的 Kindle 电子书阅读器
不是连接不上就是没有填写正确的密钥格式(尤其是有道和百度)
chatgpt api 测试的时候 无法解析返回的响应。原始数据: 这问题该怎么解决?
存在同样的问题:无法解析返回的响应。原始数据:HTTP Error 403: Forbidden
碰到了bad escape的问题:
[自动探测 > Chinese (Simplified)] 翻译 “Capital Wars: The Rise of Global Liquidity”
InputFormatPlugin: EPUB Input running
on D:\BOOK\Michael J. Howell\Capital Wars_ The Rise of Global Liq (2)\Capital Wars_ The Rise of Globa – Michael J. Howell.epub
Found HTML cover OEBPS/html/Cover.xhtml
Parsing all content…
Merging user specified metadata…
Detecting structure…
Flattening CSS and remapping font sizes…
Source base font size is 12.00000pt
Removing fake margins…
Cleaning up manifest…
Trimming unused files from manifest…
Trimming ‘OEBPS/navigation.xhtml’ from manifest
Trimming ‘OEBPS/toc.ncx’ from manifest
Trimming ‘OEBPS/css/sidebar.gif’ from manifest
Creating EPUB Output…
Translating ebook content … (this will take a while)
| Input Path: D:\BOOK\Michael J. Howell\Capital Wars_ The Rise of Global Liq (2)\Capital Wars_ The Rise of Globa – Michael J. Howell.epub
| Output Path: C:\Users\zghsy\AppData\Local\Temp\calibre_8iaonvc5\y5ch9bin.epub
翻译已完成。
Traceback (most recent call last):
File “sre_parse.py”, line 1039, in parse_template
KeyError: ‘\\D’
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File “runpy.py”, line 196, in _run_module_as_main
File “runpy.py”, line 86, in _run_code
File “site.py”, line 83, in
File “site.py”, line 78, in main
File “site.py”, line 50, in run_entry_point
File “calibre\utils\ipc\worker.py”, line 215, in main
File “calibre\utils\ipc\worker.py”, line 150, in arbitrary_n
File “calibre_plugins.ebook_translator.convertion”, line 94, in convert_book
File “calibre\ebooks\conversion\plumber.py”, line 1281, in run
File “calibre_plugins.ebook_translator.convertion”, line 88, in convert
File “calibre_plugins.ebook_translator.element”, line 328, in add_translations
File “calibre_plugins.ebook_translator.element”, line 118, in add_translation
File “re.py”, line 209, in sub
File “re.py”, line 326, in _subx
File “re.py”, line 317, in _compile_repl
File “sre_parse.py”, line 1042, in parse_template
re.error: bad escape \D at position 119
此问题已在 v2.0.3 版本中修复。
这个插件实在是太棒了,无障碍读外文资料,功德无量。
谢谢肯定。希望能做得更好。
v2.0.1
不理解,为什么它只是解释内容而不是翻译内容,我用的是默认的prompt
原文:Head position
译文:The position of the head refers to the orientation of the head in space relative to the rest of the body. The head can be in various positions depending on what the individual is doing or what their body needs. Common head positions include upright, tilted, rotated, flexed (chin towards chest), extended (chin lifted up), and turned (looking over the shoulder). Correct head posture is important for maintaining spinal alignment and reducing strain on the neck and back. A neutral head position is typically recommended, with the ears aligned over the shoulders and the chin level with the ground.
这个问题类似 Issue #20,你可以尝试在设置中修改 ChatGPT 的提示词来调整 ChatGPT 的回复,比如:Translate the content only; do not provide explanations for terms or answer questions.(只翻译内容,不要解释名词或回答问题)
完成翻译导出文件时报错:
calibre, version 6.20.0
错误: 未处理的异常: KeyError:<calibre.utils.ipc.job.ParallelJob object at 0x000002AFA9A1A980>
calibre 6.20 embedded-python: True
Windows-10-10.0.19041-SP0 Windows (’64bit’, ‘WindowsPE’)
(‘Windows’, ’10’, ‘10.0.19041’)
Python 3.10.1
Windows: (’10’, ‘10.0.19041’, ‘SP0’, ‘Multiprocessor Free’)
Interface language: zh_CN
Successfully initialized third party plugins: Ebook Translator (2, 0, 1) && Mass Search-Replace (1, 7, 3)
Traceback (most recent call last):
File “calibre\gui2\__init__.py”, line 721, in dispatch
File “calibre_plugins.ebook_translator.components.worker”, line 55, in translate_done
KeyError:
这个错误每次都会重现么?
我是批量翻译的,如果不报错,那就会正常保存到书库内,但是只要有http429,就会每个文件都翻译完毕保存后报错.还好有缓存
谢谢反馈。已排查出这个错误,会在下个版本中修复。
我也遇到了完成翻译导出文件时报错的问题,使用的是2.02版本的插件:
==============================
翻译已完成。
Traceback (most recent call last):
File “sre_parse.py”, line 1039, in parse_template
KeyError: ‘\\m’
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File “runpy.py”, line 196, in _run_module_as_main
File “runpy.py”, line 86, in _run_code
File “site.py”, line 83, in
File “site.py”, line 78, in main
File “site.py”, line 50, in run_entry_point
File “calibre\utils\ipc\worker.py”, line 215, in main
File “calibre\utils\ipc\worker.py”, line 150, in arbitrary_n
File “calibre_plugins.ebook_translator.convertion”, line 94, in convert_book
File “calibre\ebooks\conversion\plumber.py”, line 1281, in run
File “calibre_plugins.ebook_translator.convertion”, line 88, in convert
File “calibre_plugins.ebook_translator.element”, line 328, in add_translations
File “calibre_plugins.ebook_translator.element”, line 118, in add_translation
File “re.py”, line 209, in sub
File “re.py”, line 326, in _subx
File “re.py”, line 317, in _compile_repl
File “sre_parse.py”, line 1042, in parse_template
re.error: bad escape \m at position 63
此问题已在 v2.0.3 版本中修复。
自定义翻译引擎能不能支持将多段原文作为一个数组请求,而返回的译文也是一个数组这种情况呢?火山翻译的API就是这样。或者为合并翻译功能添加一个子选项,如果API原生就支持一次翻译多段文字,就按这种方式构造请求?
谢谢建议。今后的版本会考虑添加这个功能。
在使用高级模式时,我有一个很有意思的想法:
选择合并需要的段落来进行合并翻译,这样得到的翻译质量会更高.特别是DeepL,但是却不知道能不能保证格式段落和图片位置的正确.
高级模式和批量模式一样支持合并翻译,在设置中开启合并翻译并设置字符长度即可。
嗨您好,我点击translate然后显示翻译失败,原因是fail to retrieve data from translate engine API, 请问这个该怎么办呢?
尝试次数用尽后,最后应该会出现详细的错误信息,我需要通过那个信息判断问题所在。
是这个莫?
calibre, version 5.44.0 (darwin, embedded-python: True)
Translation Failed: 失敗: Failed to retreive data from translate engine API. Can not parse returned response. Raw data:
Traceback (most recent call last):
File “mechanize/_urllib2_fork.py”, line 1236, in do_open
File “http/client.py”, line 1255, in request
File “http/client.py”, line 1301, in _send_request
File “http/client.py”, line 1250, in endheaders
File “http/client.py”, line 1010, in _send_output
File “http/client.py”, line 950, in send
File “http/client.py”, line 1417, in connect
File “http/client.py”, line 921, in connect
File “socket.py”, line 808, in create_connection
File “socket.py”, line 796, in create_connection
socket.timeout: timed out
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File “calibre_plugins.ebook_translator.engines.base”, line 143, in get_result
self.br.open(request)
File “mechanize/_mechanize.py”, line 257, in open
File “mechanize/_mechanize.py”, line 287, in _mech_open
File “mechanize/_opener.py”, line 193, in open
File “mechanize/_urllib2_fork.py”, line 425, in _open
File “mechanize/_urllib2_fork.py”, line 414, in _call_chain
File “mechanize/_urllib2_fork.py”, line 1283, in https_open
File “mechanize/_urllib2_fork.py”, line 1240, in do_open
urllib.error.URLError:
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File “calibre_plugins.ebook_translator.translation”, line 73, in _translate_text
return self.translator.translate(text)
File “calibre_plugins.ebook_translator.engines.google”, line 45, in translate
return self.get_result(self.endpoint, data, headers)
File “calibre_plugins.ebook_translator.engines.base”, line 155, in get_result
raise Exception(
Exception: Can not parse returned response. Raw data:
从错误信息看是你的网络无法正常访问翻译引擎,可能需要在设置中填写并开启网络代理?
为什么翻译两句就显示没有可用的api密钥
这是自动更换 API 密钥功能导致的问题,我会尽快发一个版本修正这个错误。
要注册才能拿自己的API啊
用的就是自己的api
请问在使用chatgpt翻译的时候,经常翻译几段就弹出来“没有可用的api秘钥”,如何解决?
这是自动更换 API 密钥功能导致的问题,我会尽快发一个版本修正这个错误。
更新完之后,速度慢了,比1.3.8慢三倍.经过测试,三千个段落的书籍,原来一小时就可以完成,现在要三小时往上.
还是回滚老版本了
这是因为在之前的版本中,设置中的请求间隔没对 ChatGPT 生效。想要和之前的一样,可以前往插件的【设置 → 通用 → HTTP 请求】设置项,把“最大间隔”设为 0。
我用的DeepL (Free)
之前的表达有误。设置中的请求间隔是通用项,会应用于所有翻译引擎。
谢谢回复,翻译速度和旧版本一样了,只是开始翻译段落的”前摇”时间过长了,lol.
“前摇时间”具体是指什么?
虽然不影响翻译质量但是”前摇时间”指的是:
在日志里面显示-插件在转换为html后,翻译工作在大概一分钟后才开始翻译段落.我称之为”前摇时间”对比1.3.8,确实慢不少,一开始以为是缓存的原因,清除缓存后还是一样
新版本对过滤功能做了一些优化,提升了打开速度。
v2.0.0 版本的chatgpt翻译不好用,翻译完一句话后总是会带上(Translated from {slang} to {tlang})
请问可以增加支持azure openai api么?
插件的 v2.0.0 版本添加了对 Azure ChatGPT 的支持,请试用。
请问,如果用chatGPT合并翻译之前,先在提示词里告诉它不要吞掉分隔符({{id_11}}这类符号),它是否就能完美排版了呢?您能教我“ 不能删掉分隔符”具体要怎么表达才能让ChatGPT听懂?
有一点奇怪的是,我用ChatGPT中译日时,合并翻译设定500字、来源语言自动检测、输出语言日语,翻译完的排班完全不会出错(我让它翻译了五百多条了,排版没乱)。而一旦来源语言设置简体中文,排版就会成为一坨一坨的。同样,以此类推,我发现只要来源或输出语言选择了简体中文或英语,排版都会乱(我只会中英日三门语言,所以只试了三种)。由此可见,排版和提示词不无关系吧。
插件的 v2.0.0 版本优化了 ChatGPT 的提示词,请下载试用。
另外,新版本插件还新增 ChatGPT 的 temperature 设置,OpenAI 默认是 1,你可以尝试调低这个数值以防止它吃掉 ID,我测试的时候发现改成 0.5 效果不错。
Calibre检测不到v2.0.0,显示最新版本就是1.3.8。我的Calibre版本6.14.0
新版本发布后通常留一天的时间让用户测试,没有严重问题才会添加 Calibre 插件列表中,因此之前你没能通过 Calibre 的插件管理功能升级。刚刚插件已经上传到了 Calibre 的插件列表中,等一个小时左右应该就可以升级到最新版本了。
DeepL(Free)失效了,这两天都是“无法从翻译引擎API获取数据。”
并没有,我挂了梯子,你应该是被限制了,单IP每天有上限的
开了代理,还是不行。之前我用DeepL(Free)翻译的字符并不多,只英译中了一篇短篇小说,这也会被限制吗?
我倒是可以,已经翻了接近两百本书了,虽然经常会断,换个节点又能继续用了
破案了,只要把目标语言设置成英语(英式)或英语(美式)就不行。如果要翻译成英语的话,目标语言直接选英语就可以了