
Ebook Translator:用 Calibre 翻译多格式双语对照电子书

- 新增功能:在审阅编辑器中添加行号和同步滚动
- 新增功能:为 Gemini 添加波斯语支持
- 新增功能:改进模型获取提示的清晰度
- 修复:修复导致配置迁移错误的错误
- 修复:修复阻止转换 PNG 和 SRT 文件的错误
- 其他错误修复和功能增强
Ebook Translator 是书伴开发的一款 Calibre 插件,可以将不同格式不同语言的电子书翻译成指定语言(原文译文对照)指定格式的电子书,支持 Google、ChatGPT 和 DeepL 翻译引擎。
在日常的生活、工作或学习中,如果在阅读或翻译外文电子书的过程中需要频繁使用翻译软件,在内容和翻译软件之间来回切换,可能会成为一件颇为痛苦的事。Ebook Translator 插件借力 Calibre 对电子书的强大处理功能和翻译引擎对多种语言的翻译支持,可以轻松将译文添加到原文段落之后,如下图那样形成双语对照,方便辅助对原文的理解或作为译制材料时的参考。

▲ Ebook Translator 插件翻译的电子书效果
借助 Calibre 对多种电子书格式的灵活支持,进行翻译时,你可以自由地选择输入输出格式,比如把 TXT 翻译成为 TXT 或 EPUB,把 PDF 翻译成 PDF 或 DOCX。
Ebook Translator 插件源代码使用 GPL v3 许可证。插件项目托管在 GitHub 上。
一、功能简介
★ Ebook Translator 插件主要包含以下功能:
- 支持“批量模式”和“高级模式”两种翻译模式,应用于不同使用场景
- 支持所选翻译引擎所支持的语言(如 Google 翻译支持 134 种)
- 支持多种翻译引擎,包括 Google 翻译、ChatGPT 以及 DeepL
- 支持自定义翻译引擎(支持解析 JSON 和 XML 格式响应)
- 支持所有 Calibre 所支持的电子书格式(输入格式 48 种,输出格式 20 种)
- 支持批量翻译电子书,每本书的翻译过程同时进行互不影响
- 支持缓存翻译内容,在请求失败或网络中断后无需重新翻译
- 提供大量自定义设置,如将翻译的电子书存到 Calibre 书库或指定位置
★ Ebook Translator 插件支持翻译的语言:
- Google 翻译支持的语言列表
- DeepL 翻译支持的语言列表
- ChatGPT 具体支持语言不详
- 有道翻译支持的语言列表
- 百度翻译支持的语言列表
★ Ebook Translator 插件支持的输入格式:
EPUB, AZW3, AZW4, MOBI, PDF, DOCX, TXT, MARKDOWN, RTF, RECIPE, HTML, HTM, XHTML, XHTM, TXTZ, CB7, ODT, RAR, FBZ, CBC, SHTM, TEXT, SHTML, POBI, UPDB, OPF, TCR, PML, PDB, CHM, SNB, LRF, LIT, RB, DOWNLOADED_RECIPE, CBR, DJV, DJVU, MD, AZW, TEXTILE, DOCM, HTMLZ, PMLZ, CBZ, ZIP, PRC, FB2,SRT,PGN
★ Ebook Translator 插件支持的输出格式:
EPUB, AZW3, MOBI, KFX, PDF, DOCX, TXT, RTF, OEB, TCR, PDB, SNB, LRF, TXTZ, LIT, RB, HTMLZ, PMLZ, ZIP, FB2,SRT,PGN
二、安装插件
首先确保你的操作系统已经安装了 Calibre,然后通过一下任意方式安装本插件:
【方法一】通过 Calibre 安装
- 打开 Calibre 并依次点击其菜单【 首选项… → 插件 → 获取新的插件 】;
- 在插件列表中选中 Ebook Translator 然后点击 【 安装 】 按钮(请留意,首次安装此插件时,要选择把图标显示在主工具栏上);
- 最后关闭并重新打开 Calibre 即可正常使用。
【方法二】通过插件文件安装
NAME: Ebook-Translator-Calibre-Plugin_v2.2.0.zip
MD5: 4eda05385bf2f49d1b8a066b9795e3ab
SHA1: e9bcfc0d02c51dc7dd7d9de9a1f4b0c12e3f6ba0
- 首先在通过以上链接下载插件文件;
- 然后打开 Calibre 并依次点击其菜单【首选项 → 插件 → 从文件加载插件】;
- 在弹出的对话框中选择下载的扩展名为 .zip 的插件文件完成安装(请留意,首次安装此插件时,要选择把图标显示在主工具栏上);
- 最后关闭并重新打开 Calibre 即可正常使用。
如果想安装最新版本,可以访问 https://translator.bookfere.com 点击按钮【Rolling Release】下载。注意,最新版本在每次提交代码时自动生成,未经过严格测试,可能会存在错误。
如果安装插件后,插件图标未出现在 Calibre 的主工具栏上,可以依次点击 Calibre 的菜单【首选项 → 工具与菜单】,在弹出的对话框中点击下拉菜单并选择“主工具栏”,然后在左栏找到并选中插件图标,点击中间的右箭头按钮【>】将其添加到右栏,最后点击【应用】按钮即可。
三、使用方法
Ebook Translator 提供了两种翻译模式,在开启缓存状态下两者共享同一缓存数据。
1、高级模式
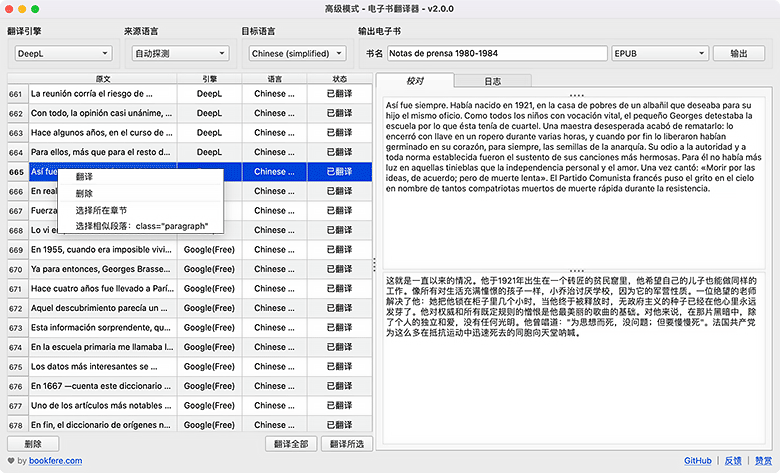
- 在 Calibre 书库中选中要推送的电子书,点击 Calibre 主工具栏上的【翻译书籍】图标按钮,或点击图标下拉菜单选择【高级模式】;
- 在弹出的提示框点击选择“高级模式”(首次打开);
- 选择“输入格式”和“输出格式”,点击【开始】进入“高级模式”翻译主界面;
- 点击【删除】按钮删除需要忽略翻译的选中段落(可选);
- 通过以下两种方式进行翻译:
- 点击【翻译所选】按钮翻译选中的段落
- 点击【翻译全部】按钮翻译全部电子书内容
- 翻译完成后,在右方“校对”区域,通过编辑下方文本并点击【保存】,可以更改翻译结果;
- 点击【输出】按钮,存储翻译完成后的电子书。输出任务将被推送添加到 Calibre 的任务队列。
2、批量模式
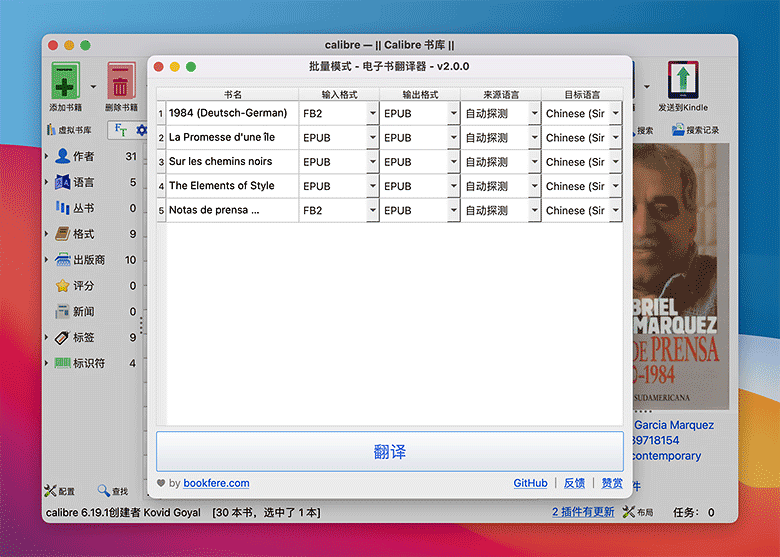
- 在 Calibre 书库中选中要推送的电子书,点击 Calibre 主工具栏上的【翻译书籍】图标按钮,或点击图标下拉菜单选择【批量模式】;
- 在弹出的提示框点击选择“批量模式”(首次打开);
- 进入插件主界面,在这里你可以修改“书名”(作为保存文件时使用的文件名),分别为每一本书选择“输入格式”、“输出格式”、“来源语言”(一般情况下“自动探测”即可满足需求)、“目标语言”(默认使用 Calibre 界面当前所用的语言);
- 点击下方的【翻译】按钮即可开始翻译。
插件会将每本电子书的翻译任务推送添加到 Calibre 的任务队列,你可以通过点击 Calibre 右下角的【任务】查看推送详情,双击任务条目可以进入日志实时查看正在翻译的内容。
三、插件设置
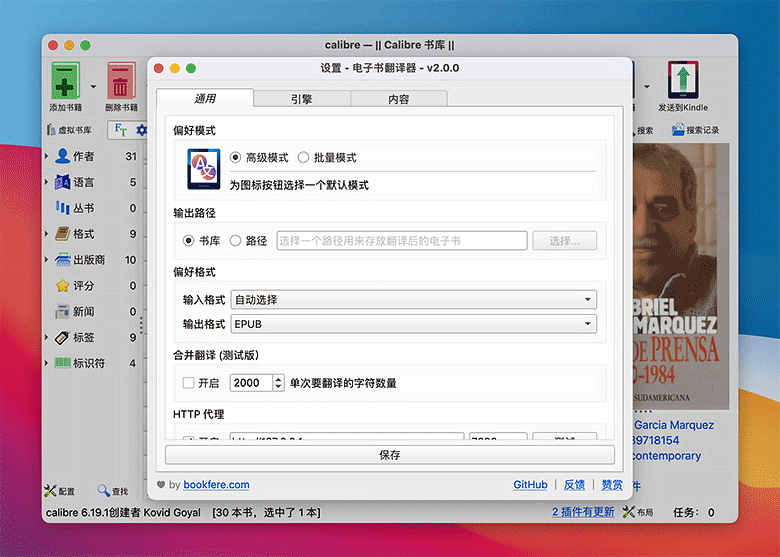
▲ Ebook Translator 通用设置
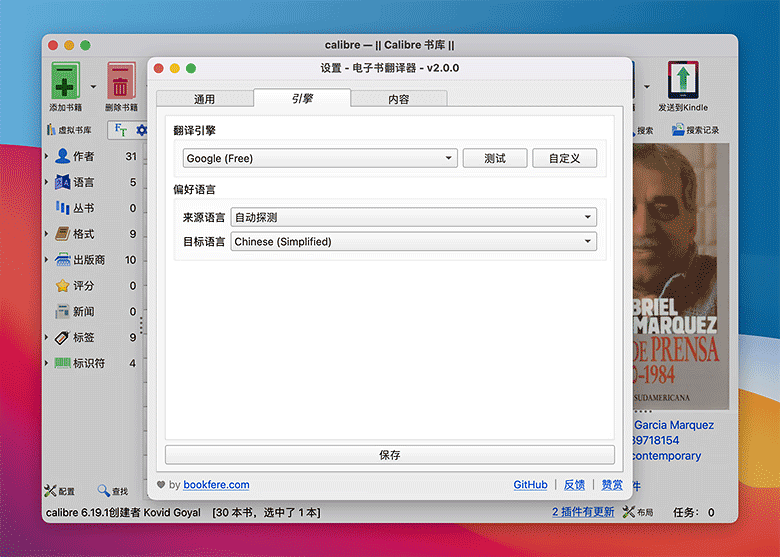
▲ Ebook Translator 引擎设置
▲ Ebook Translator 内容设置
有关设置内容的详细说明请查阅 Ebook Translator 项目的 Wiki 页面。
五、注意事项
开发 Ebook Translator 插件测试用的 Calibre 版本是 3.48 和最新版版本,因此理论上插件在 3.x 到 6.x 版本的 Calibre 中都能正常使用,但是如果版本低于 3.x,可能无法正常使用。
尽管 Ebook Translator 插件在发布会尽可能测试,但仍无法保证在任何情况下不会出现问题。
如果你在使用插件的过程中遇到了问题或有好的建议,欢迎报告错误或提交功能请求。
六、常见问题
1、翻译文件丢失
有些用户反馈翻译完成后无法打开文件,此问题通常发生在 Windows 系统上。在 Windows 系统中,有一个功能叫做 “存储感知”,它会自动清理长时间运行程序的临时文件。
为避免此问题,请通过插件的缓存管理器为缓存另外指定文件夹(请勿选择任何临时目录)。
2、翻译速度太慢
普通翻译服务(如 Google Translate)翻译 1000 个段落通常仅需不到 1 分钟的时间。如果你使用的是 ChatGPT 之类的生成式 AI,耗时则有较大的差异,建议根据服务的速率限制在设置中修改并发请求和请求间隔以加快翻译速度。另外,也可开启合并段落功能大幅提升翻译速度。
3、合并翻译效果
在使用 ChatGPT 时合并翻译功能表现较差,这是因为插件会在合并后的文本中添加标记,由于无法保证 ChatGPT 翻译这些文本后仍会保留这些标记,因此无法保证最终的翻译效果。因此,如果要使用的 ChatGPT 翻译电子书,不建议开启合并翻译功能。
© 「书伴」原创文章,转载请注明出处及原文链接:https://bookfere.com/post/1057.html
延伸阅读
- [每周一书]《最好的辩护》法律人的逻辑与精神
- Kindle 固件版本号查询方法及固件更新步骤
- 在尝试 Kindle Paperwhite 之前我曾抵触过电子书阅读器
- [每周一书]《你一定爱读的极简欧洲史》
- 鲁迅作品集大全免费正版 Kindle 电子书
- [读书笔记] 如何成为自己的营养师(脂肪篇)
- 亚马逊新款 558 入门版 Kindle 开箱图赏
- [每周一书]《WHAT IF》那些古怪又让人忧心的问题
- 图解 Kindle Paperwhite 电子书阅读器工作原理
- 读书也跟风:跟着诺贝尔奖读书靠不靠谱?
- 亚马逊 Kindle 锁屏正在为劣质 AI 生成电子书展示广告
- [每周一书]《呼兰河传》生与死的悲歌
- Kindle 为何如此耐用?亚马逊硬件测试工程师独家为你揭秘
- [每周一书]《独裁者手册》带你真正理解政治
- [每周一书] 解读反精英现象《美国生活中的反智主义》
使用DeepL(Free)翻译报错:
Traceback (most recent call last):
File “calibre_plugins.ebook_translator.engines.base”, line 171, in get_result
br.open(request)
File “mechanize/_mechanize.py”, line 257, in open
File “mechanize/_mechanize.py”, line 313, in _mech_open
mechanize._response.get_seek_wrapper_class..httperror_seek_wrapper: HTTP Error 429:
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File “calibre_plugins.ebook_translator.components.engine”, line 66, in translate_text
translation = self.translator.translate(text)
File “calibre_plugins.ebook_translator.engines.deepl”, line 125, in translate
return self.get_result(
File “calibre_plugins.ebook_translator.engines.base”, line 181, in get_result
raise Exception(_(‘Can not parse returned response. Raw data: {}’)
Exception: 无法解析返回的响应。原始数据:
Traceback (most recent call last):
File “calibre_plugins.ebook_translator.engines.base”, line 171, in get_result
br.open(request)
File “mechanize/_mechanize.py”, line 257, in open
File “mechanize/_mechanize.py”, line 313, in _mech_open
mechanize._response.get_seek_wrapper_class..httperror_seek_wrapper: HTTP Error 429:
使用免费的翻译引擎,一旦出现 429 错误,就意味着需要加大请求间隔,同时不要使用并发请求。
多谢
插件翻译的文件阅读卡顿报错怎么解决? 翻译的文件超链接丢失。目录翻译有吗?
calibre, version 6.23.0
错误: 未处理的异常: TimeoutError:Timed out waiting for: pause
calibre 6.23 embedded-python: True
Windows-10-10.0.22631-SP0 Windows (’64bit’, ‘WindowsPE’)
(‘Windows’, ’10’, ‘10.0.22631’)
Python 3.10.1
Windows: (’10’, ‘10.0.22631’, ‘SP0’, ‘Multiprocessor Free’)
Interface language: zh_CN
Successfully initialized third party plugins: Ebook Translator (2, 1, 1)
Traceback (most recent call last):
File “calibre\gui2\viewer\tts.py”, line 95, in action
File “calibre\gui2\viewer\tts.py”, line 123, in stop
File “calibre\gui2\tts\windows.py”, line 154, in stop
File “calibre\utils\windows\winspeech.py”, line 442, in pause
File “calibre\utils\windows\winspeech.py”, line 424, in wait_for
TimeoutError: Timed out waiting for: pause
卡顿的问题可能和书本身有关系。译文目前不会保留链接。目录只翻译内容中的目录,Kindle“前往”导航中的目录不会翻译。这个错误提示是在做什么操作时出现的?
是翻译后的书籍 操作朗读是 就会报这个错误
请问翻译时候出现:无法解析返回的响应。原始数据:应该怎么处理呢?谢谢.网络正常,已科学上网,用的chatgpt的api
建议更换 IP 再试试看,因为有些网络代理线路对 ChatGPT 不可用。
启用词汇表后,只保留译文情况,输出为:
关于作者 约翰-多克尼亚斯 是2021年不列颠哥伦比亚省冠军。他曾在大太平洋公开赛、兰利公开赛和2017年加拿大U18锦标赛等多项强手如林的比赛中夺冠。约翰是一名国际象棋教师,拥有超过9年的教学经验,并为著名的国家国际象棋出版物做注释。维多利亚-多克尼亚斯(Victoria Doknjas),工商管理硕士,是北美青年国际象棋锦标赛(2014年和2017年)和2015年世界青年和少年国际象棋锦标赛(希腊)的加拿大代表团团长。她赢得了2016年加拿大高级女子冠军头衔,并共同创办了青少年国际象棋学院。作者:John Doknjas 现代贝诺尼 西西里纳伊多夫 重演 (与Joshua Doknjas合著)
中间的替换代码显示不出来
见 issue #91。
报错,不知何意。
calibre, version 6.23.0
错误: 未处理的异常: TypeError:stat: path should be string, bytes, os.PathLike or integer, not NoneType
calibre 6.23 embedded-python: True
macOS-13.4.1-arm64-arm-64bit Darwin (’64bit’, ”)
(‘Darwin’, ‘22.5.0’, ‘Darwin Kernel Version 22.5.0: Thu Jun 8 22:22:23 PDT 2023; root:xnu-8796.121.3~7/RELEASE_ARM64_T6020’)
Python 3.10.1
OSX: (‘13.4.1’, (”, ”, ”), ‘arm64’)
Interface language: zh_CN
Successfully initialized third party plugins: Gather KFX-ZIP (from KFX Input) (2, 2, 0) && Package KFX (from KFX Input) (2, 2, 0) && Douban Books (3, 2, 0) && Ebook Translator (2, 1, 1) && KFX metadata reader (from KFX Input) (2, 2, 0) && KFX Input (2, 2, 0) && Set KFX metadata (from KFX Output) (2, 0, 0) && KFX Output (2, 0, 0) && KOReader Sync (0, 5, 2)
Traceback (most recent call last):
File “calibre_plugins.ebook_translator.batch”, line 122, in
lambda: self.translate_ebooks(self.ebooks))
File “calibre_plugins.ebook_translator.batch”, line 135, in translate_ebooks
if not to_library and not os.path.exists(output_path):
File “genericpath.py”, line 19, in exists
TypeError: stat: path should be string, bytes, os.PathLike or integer, not NoneType
这是在做什么操作的时候出现的错误?输出的路径是 Calibre 书库还是指定的目录?
不知何故,calibre升级,插件升级后,一切正常了。可以顺当的完成翻译到打包AZW3的全过程。
这个版本批量翻译书籍超过重试次数后,自动输出未翻译完全的书籍.
这就会导致每一次都要翻日志,看看是不是完成翻译还是未完成翻译,然后再重新翻译
因为我用的deepl,free.经常会受到每日限制.我自己通过不断改IP地址逃脱限制
以前出错了,我还能知道哪些没翻译完成,继续翻译
你的预期是当使用批量翻译的时候,一旦出现错误就让它停止,而不是忽略错误直至完成对吗?
是的,高级模式可以停止,但是批量模式一旦错误超过设定重试次数就会自动输出未完成的书籍.
因为用的deeplfree,所以经常会错误
好的,下个版本会改进。
为啥你的deeplfree可以用?
打开缓存时显示错误代码:
calibre, version 6.23.0
错误: 未处理的异常: TypeError:int() argument must be a string, a bytes-like object or a real number, not ‘NoneType’
calibre 6.23 embedded-python: True
Windows-10-10.0.19041-SP0 Windows (’64bit’, ‘WindowsPE’)
(‘Windows’, ’10’, ‘10.0.19041’)
Python 3.10.1
Windows: (’10’, ‘10.0.19041’, ‘SP0’, ‘Multiprocessor Free’)
Interface language: zh_CN
Successfully initialized third party plugins: Ebook Translator (2, 1, 1)
Traceback (most recent call last):
File “calibre_plugins.ebook_translator.ui”, line 131, in show_cache
File “calibre_plugins.ebook_translator.cache”, line 37, in __init__
File “calibre_plugins.ebook_translator.cache”, line 104, in table_widget
File “calibre_plugins.ebook_translator.cache”, line 201, in __init__
File “calibre_plugins.ebook_translator.cache”, line 206, in wrapper
File “calibre_plugins.ebook_translator.cache”, line 228, in refresh
File “calibre_plugins.ebook_translator.lib.cache”, line 120, in get_list
TypeError: int() argument must be a string, a bytes-like object or a real number, not ‘NoneType’
谢谢反馈,这个错误会在下个版本修复。
关于ChatGPT 用合并翻译,再版本1.3.8及之前有一个取巧的方式:观察没有标记的段落(即排版错误翻译挤成一坨的地方),稍微改变下原文。不需要修改太多,比如把某个逗号替换成句号,或者加一个空格符即可。接下来重新用ChatGPT翻译这本书,之前排版正确的段落会从缓存中提取,错误的段落会重新翻译。
但是这种方法再2.0.0之后失效了。请问可以修复吗?
出现这种情况,是旧版本没有检查缓存是否重复的一个副作用,因此在新版本中不再有效。新版本中的高级模式不能解决这个问题吗?
HTTP请求中的重试次数能否设置的均匀一些,比如每隔5分钟重试一次,而不是重复次数越多等待的时间越长?
谢谢反馈!后面的版本会考虑增加这个选项。
遇到了一个问题,用高级模式的Google(Free)把简体转换为繁体时,一级目录正常,而二级目录不能正常关联,点击目录时无法转到正确的章节,请问怎么解决?
是页面导航还是 Kindle 的“前往”导航?
两个导航都有问题。
一级目录(第一章、第二章……)可以正常关联,而二级目录(每个章节里的小节一、二……)不能正常关联。
虽然这个问题可以用Sigil修复,但还是想反馈一下,如果表述不准确请见谅。
能否将翻译后的电子书发到书伴邮箱 ,以便测试。
无法解析返回的响应。原始数据:’utf-8′ codec can’t decode byte 0xc4 in position 4: invalid continuation byte
–
是不是DeepL通道封掉了?
不是。不知 DeepL 改动的什么导致原来的请求数据出了问题,近两天要发布的版本会修复这个问题。
之前一直使用deepl(free) ,但这两天忽然不行了(测试了谷歌free,还是可以连接上)
显示说是:
无法解析返回的响应。原始数据:’utf-8′ codec can’t decode byte 0xc4 in position 4: invalid continuation byte
这个问题在新版本中已解决。新版本正在测试,估计近两天就会发布。
谢谢回复,原来不是我一个人的问题啊。那就等新版本了,辛苦了。
我不小心把chatgpt openai的提示词给删了,请问它原始的提示词是什么?
删除提示词输入框中的所有文字,可以看到默认提示词。删除提示词也没关系,插件会自动使用默认提示词。
GPT3.5测试正常,GPT4测试显示无法解析返回的响应。原始数据:HTTP Error 404: Not Found
这是新的报错
翻译已完成。
Traceback (most recent call last):
File “sre_parse.py”, line 1039, in parse_template
KeyError: ‘\\U’
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File “runpy.py”, line 196, in _run_module_as_main
File “runpy.py”, line 86, in _run_code
File “site.py”, line 83, in
File “site.py”, line 78, in main
File “site.py”, line 50, in run_entry_point
File “calibre\utils\ipc\worker.py”, line 215, in main
File “calibre\utils\ipc\worker.py”, line 150, in arbitrary_n
File “calibre_plugins.ebook_translator.convertion”, line 94, in convert_book
File “calibre\ebooks\conversion\plumber.py”, line 1281, in run
File “calibre_plugins.ebook_translator.convertion”, line 88, in convert
File “calibre_plugins.ebook_translator.element”, line 328, in add_translations
File “calibre_plugins.ebook_translator.element”, line 118, in add_translation
File “re.py”, line 209, in sub
File “re.py”, line 326, in _subx
File “re.py”, line 317, in _compile_repl
File “sre_parse.py”, line 1042, in parse_template
re.error: bad escape \U at position 86
这个错误同网友 Alex 和 Xiao 的反馈。今天要发布的 v2.0.3 版本会包含此错误的修复。
那么修复的版本缓存会失效吗?上次1.8的升级到2.0就失效了
这次不会。只有当需要修改和抽取内容或缓存相关的功能,且无法兼容老版本时,才会导致老版本缓存失效。今后更新时,如果出现不兼容老版本缓存的情况,会在发布时说明。
翻译完成后无法保存,保存任何格式都会
————————————————–
译文:
==============================
翻译已完成。
Traceback (most recent call last):
File “runpy.py”, line 196, in _run_module_as_main
File “runpy.py”, line 86, in _run_code
File “site.py”, line 83, in
File “site.py”, line 78, in main
File “site.py”, line 50, in run_entry_point
File “calibre\utils\ipc\worker.py”, line 215, in main
File “calibre\utils\ipc\worker.py”, line 150, in arbitrary_n
File “calibre_plugins.ebook_translator.convertion”, line 94, in convert_book
File “calibre\ebooks\conversion\plumber.py”, line 1281, in run
File “calibre_plugins.ebook_translator.convertion”, line 88, in convert
File “calibre_plugins.ebook_translator.element”, line 328, in add_translations
File “calibre_plugins.ebook_translator.element”, line 127, in add_translation
File “src/lxml/etree.pyx”, line 3233, in lxml.etree.XML
File “src/lxml/parser.pxi”, line 1913, in lxml.etree._parseMemoryDocument
File “src/lxml/parser.pxi”, line 1793, in lxml.etree._parseDoc
File “src/lxml/parser.pxi”, line 1082, in lxml.etree._BaseParser._parseUnicodeDoc
File “src/lxml/parser.pxi”, line 615, in lxml.etree._ParserContext._handleParseResultDoc
File “src/lxml/parser.pxi”, line 725, in lxml.etree._handleParseResult
File “src/lxml/parser.pxi”, line 654, in lxml.etree._raiseParseError
File “”, line 1
lxml.etree.XMLSyntaxError: Premature end of data in tag p line 1, line 1, column 45
能否发送出错的电子书到书伴邮箱 以便测试。