
如何将从 Kindle 中国电子书商店购买的电子书备份到本地

提示:亚马逊中国区已经停止 Kindle 电子书下载。
昨日亚马逊中国(amazon.cn)通过邮件向 Kindle 用户发送了关于“Kindle 中国电子书店将于 2023 年 6 月 30 日停止运营”的业务调整通知,根据亚马逊的业务调整政策,用户需要在 2024 年 6 月 30 日之前,也就是在两年内,将自己购买的电子书下载到本地设备进行保存。
为确保小伙伴们的合法权益不受损害,书伴会在本文中介绍如何保全自己花钱购买的电子书。
一、注意事项
要备份在亚马逊中国 Kindle 电子书商店购买的电子书,最好的方式就是用网页浏览器访问亚马逊中国官网,进入“管理我的内容和设备”页面,通过电子书列表中提供的下载功能将电子书文件下载到本地,通常下载下来的文件是 AZW3 或 AZW 格式,含有书籍完整内容。
切忌通过 Kindle 设备直接下载电子书进行备份,这是因为 Kindle 为了优化电子书的阅读体验,会对通过此种方式下载电子书做额外处理,这会导致电子书的全部内容(如图片)不再存放在单个文件中,比如在 Kindle 的 documents 目录中常见到扩展名为 .kfx 的电子书文件。
二、手动下载
从亚马逊中国官方网站下载你所购买电子书的具体步骤如下图所示:
- 访问网址 https://www.amazon.cn/hz/mycd/myx/,登录亚马逊中国账号;
- 进入“管理我的内容和设备”页面的电子书列表;
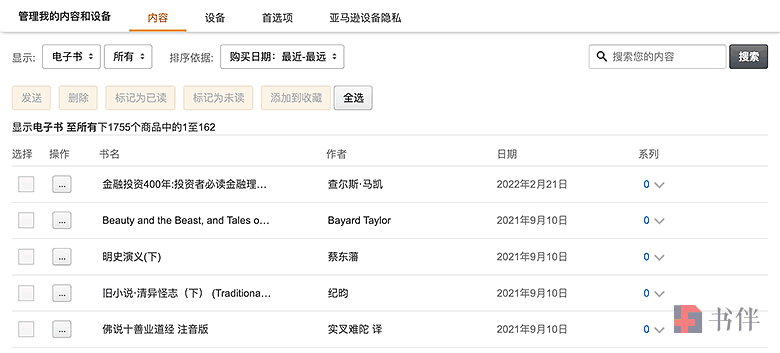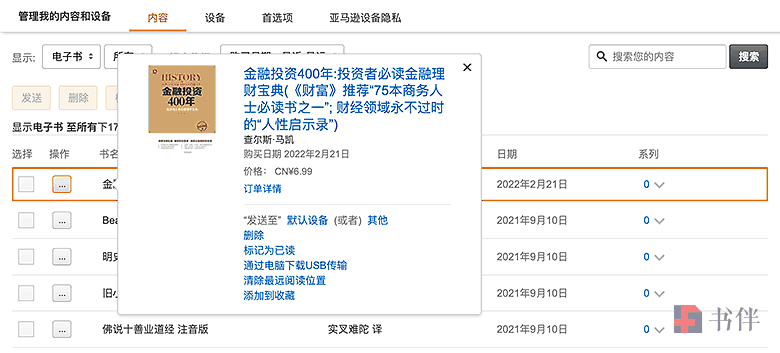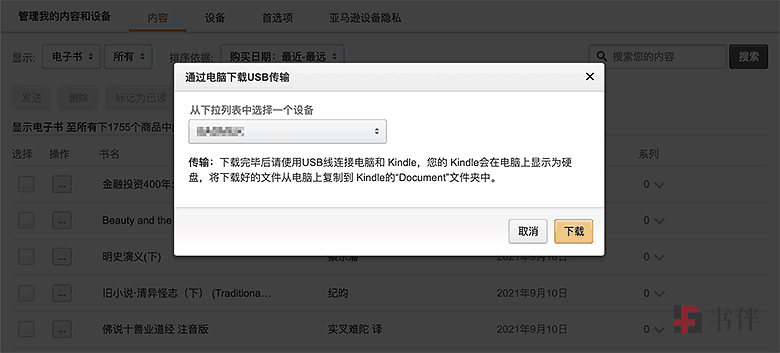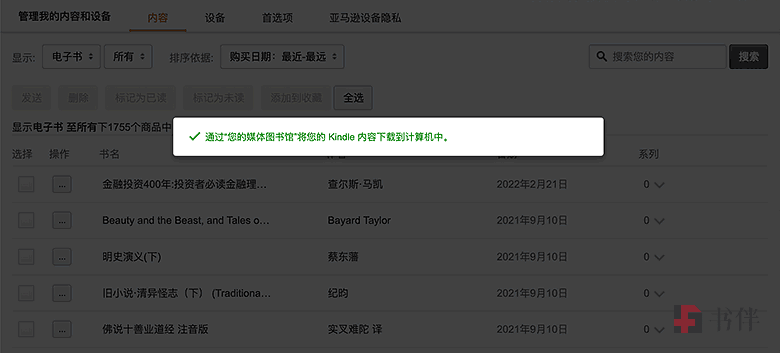
- 点击列表中电子书标题左侧的【…】按钮;
- 在弹出的悬浮窗中点击“通过电脑下载USB传输”;
- 选择要阅读此电子书的 Kindle 设备名称;
- 最后点击【下载】按钮,即可将电子下载到本地。
通过上述方式下载电子书,有一个硬性条件,就是你所登录的账号名下必须有绑定的 Kindle 设备,手机、平板或电脑版 Kindle 应用都无法通过这种方式下载,只能在应用中下载电子书。
不同系统平台的 Kindle 应用存放电子书的位置不同,具体可参考以下列表:
- Windows:C:\Users\YOURNAME\Documents\My Kindle Content
- macOS:/Users/YOURNAME/Library/Application Support/Kindle/My Kindle Content/
- Android:/data/media/0/Android/data/com.amazon.kindle/files/
亚马逊没有提供个人文档下载方式,你可通过 Kindle 设备或应用下载个人文档。
三、批量下载
如果不想手动逐一下载,可使用书伴编写的自动批量下载脚本。具体用法:用鼠标拖放下方链接到网页浏览器书签栏,访问 https://www.amazon.cn/hz/mycd/myx/,登录账号并进入电子书列表,点击“自动下载 Kindle 电子书”书签开始下载。该脚本支持自动翻页,无需手动干预。
自动下载 Kindle 电子书↑ 请将此小书签拖放到浏览器书签栏使用 ↑
脚本会先等待电子书页面列表显示完整再下载,因此初次点击后需要等待一会儿,请勿重复点击。脚本默认每 20 秒下载一次,你可在拖放小书签之前通过上面的输入框修改“下载间隔”的数值,根据下载速度加大或减少间隔,以确保电子书能够下载成功。另外,你可以打开网页浏览器的开发者工具通过“控制台”(Console)查看下载详情。如果想中止下载,刷新一下页面即可。
注意,此脚本只是模拟了手动点击下载的操作,理想情况下,电子书应在设定的时间间隔内完成下载,如果网络不够通畅,加上浏览器对同时下载文件个数的限制,很可能会产生遗漏。遇到这种情况,可使用勾选了“启用去重功能”的小书签,这样运行脚本时会提示你选择已下载电子书所在的文件夹,从而在下载时检查文件夹中的电子书名,如果存在就会忽略,以达到去重功能。由于电子书列表页显示的书名和实际下载的文件名有出入,去重功能比较粗略。
▲ 在 Chrome 的开发者工具中查看自动下载详情
四、移除 DRM
需要注意的是,亚马逊为 Kindle 电子书添加了 DRM[1],这会限制电子书的通用性,也就是说你所下载的电子书文件仅能在下载该电子书时所选择的 Kindle 设备中阅读,无法在其它电子书阅读器或电子书阅读软件阅读,即便是绑定在同一账号下的其它 Kindle 设备也是如此。
对于此问题,如果亚马逊中国持续提供内容的网络访问权,为电子书添加 DRM 的弊端还算不太明显,但是一旦出现停止网络服务这种极端情况,问题就显得比较尖锐了。由于电子书必须在某个特定设备才能阅读,如果将来你的 Kindle 设备故障失修,除非去除 DRM 保护,你将永远失去对这些你所购买的电子书的使用权限,这显然侵犯了 Kindle 用户作为消费者的权利。
要去除电子书的 DRM 保护,这里推荐使用软件组合:Calibre + DeDRM 插件,即先安装 Calibre,再为 Calibre 安装 DeDRM 插件,即可利用 Kindle 设备序列号为电子书移除 DRM(注意,如果你有多台 Kindle 设备,且不确定下载的电子书用的是哪一台,最好是将它们的序列号都添加到 DeDRM 的设置中。上面的电子书自动下载脚本使用的是默认选择的 Kindle 设备)。
- 下载 Calibre:官方下载页面 | Github 发布页
- 下载 DeDRM 插件:分叉版本 | 原始版本(已停止维护)
* 提示:用电脑或移动 Kindle 应用所下载电子书,去除 DRM 的方式有所不同,详情可参考 DeDRM 的 Wiki 页面。
注意,移除 DRM 是为了维护自己的合法权益,为避免触犯版权方的权益,请勿分发到互联网上。为保护个人隐私及电子书文件不被外泄,建议避免使用任何在线形式的 DRM 去除工具。
五、其它问题
如果你没有 Kindle 设备,仅使用手机、平板或电脑版 Kindle 应用购买电子书,目前没有特别好的方法可以保全你所购买的电子书,在亚马逊中国停止服务后,你需要确保安装了 Kindle 应用的设备无恙,且没有误删 Kindle 应用。对于此类用户建议向亚马逊中国提出保全诉求。
© 「书伴」原创文章,转载请注明出处及原文链接:https://bookfere.com/post/983.html
延伸阅读
- Calibre 转换 TXT 文件出现 Errno 21 错误的解决方法
- [每周一书]《无价》商业行为背后的定价理论
- [每周一书]《自由选择》地球人不可不读的书
- Kindle 固件降级教程:支持部分已越狱 Kindle 设备
- [每周一书] 正在消失中的《最后的耍猴人》
- 亚马逊 Kindle 全系列更新,含首款彩屏 Kindle Colorsoft
- [每周一书] 十四位法官对《洞穴奇案》的判决书
- 微软已解决 Kindle 连接电脑出现的蓝屏问题
- 蔡志忠:读书是回报率最高的投资
- 给 Kindle 一个家?亚马逊或将开设一家实体书店
- 制作 KF8 标准电子书示例(下):图片与背景
- [每周一书] 人是为了活着本身而《活着》
- [每周一书]《失控》全人类的最终命运和结局
- [每周一书] 轻松科普《癌症·真相:医生也在读》
- 解读哲学家:牛津通识读本系列丛书摘选推荐
请问Send to Kindle、邮箱推送的个人文档,可否批量下载到PC中?
亚马逊没有为个人文档提供下载功能,应该是不能的。
“中国官网进入“管理我的内容和设备”页面,通过电子书列表中提供的下载功能将电子书文件下载到本地,通常下载下来的文件是 AZW3 或 AZW 格式,含有书籍完整内容。”
从中亚下载的购买电子书导出都是AZW3格式的,然而邮件推送美亚账号只能支持AZW格式,大哭。
然而备份的个人文档(用中亚账号推送的原文件txt格式、mobi格式或AZW3格式均有)很神奇地一部分是AZW3格式,一部分是AZW格式,捉摸不透转出格式的规律。
对于从下载到的 AZW3 格式电子书,你可以用 KindleUnpack 对其进行拆解,就可以得到保持原有排版的可以直接推送的 EPUB 格式。对于个人文档,如果你当时推送的是 MOBI7 格式,就会被转换成 AZW 格式,如果推送的是 MOBI8 就会被转换成 AZW3 格式。
非常感谢,我试试看
另外,之前留言中提到的,高频出现的错误(批量下载时,控制台中高频出现以下报错:
XMLHttpRequest cannot load https://www.amazon.cn/hz/mycd/ajax due to access control checks.))会在下载以下书籍时重复、反复发生——
[Log] Downloading: 亮剑(某瓣9.5分霸屏抗战神剧《亮剑》原著小说。电视剧只拍出原著的不到一半,更多精彩尽在书中。) (ref=z_cn, line 1)
[Log] Downloading: 最寒冷的冬天:美国人眼中的朝鲜战争(朝鲜战争类畅销冠军,风靡学术界、企业界巨作,美国知识界对朝鲜战争最深刻的思考。) (ref=z_cn, line 1)
最后,我这里400本多书,无论怎么反复下载,下载下来总是只有360多本,不知道问题出在哪里
脚本并没有发起 Ajax 请求,这些请求电子书列表页面在获取电子书项目时发起的,正常情况下应该不会报错,估计你无法下载的那些书就是受这个影响。电子书列表每页应该是 200 项,你可以手动向下滑动一下滚动条,看它会不会出现同样的错误。
问题依然存在。并且总是在“那特定的几本书”上,脚本使页面进入一个报错的页面。
那几本书能够手动下载吗?
果然,这几本书手动下载有问题。所以并不是脚本,而是亚马逊的问题。
谢谢书伴
另外还发现一个问题,有部分书重复下载检测是无法判定的,即会重复下载,例如:
工作、消费主义和新穷人(豆瓣年度读书榜、知乎年度书单榜首).azw3
人类简史三部曲_尤瓦尔·赫拉利作品(套装共3册)(烧脑神书,颠覆你的世界观!错过这套书的人将错过未来).azw3
窄门 (纪德文集:田园交响曲+人间食粮+窄门+背德者(套装共4册))
是的,去重功能很粗略,只是简单的将页面上显示的标题和下载后的电子书文件名进行对比,但是实际情况是,页面上的标题和电子书文件名并不是完全一致的,比如页面上显示的标题带有括号里的内容,下载后的却没有,就无法准确判断了。
批量下载时,控制台中高频出现以下报错:
XMLHttpRequest cannot load https://www.amazon.cn/hz/mycd/ajax due to access control checks.
会影响下载吗?如果不影响则可以忽略。
谢谢你,自动下载的方法很有用!不到500本总共用了两个多小时。
原先在网上看到有用python下载的方法,但我电脑上的界面跟展示的怎么都不一样,该找的代码也找不到,最后在这里找到了非常易懂的方法。
感谢!
X-ray怎么办?以后停止运营之后
Kindle 退出中国后,电子书依赖网络服务的相关数据都无法获取了。
中断之后怎么跳过已经下载的 哭
脚本已添加去重功能,你可以删掉旧的小书签,勾选“去重功能”再重新拖放小书签。使用时,选择存放已下载电子书的文件夹,脚本会就会在下载时自动忽略这些已下载的电子书。
我自己挖了代码手动从页面下载了awz3格式的书,也利用kindle for PC下载了一份awz的。 大概比对了一下,感觉两者大小一样应该是一样的, 但是PC同时还下载了azw.res文件。 翻了kindle内的文件, 大部分是kfx的, 还很多是分散在sdr文件夹里面。现在很纠结备份到底用哪个版本呢。
如果有足够的存储空间,可以都留着,否则建议只备份从页面下载的 AZW3 格式。
文中提供的脚本很好用,不过需要注意一点:电子书列表内如果有不能下载的样章会报错。实测删除样章即可(筛选可能也有用但是没试过)。
谢谢反馈,已修正这个问题,现在脚本会自动忽略样章。
能不能麻烦书伴开个转区美亚日亚教程?kindle多平台同步用户表示没有这个优势基本kindle放弃治疗了/(ㄒoㄒ)/~~只能指望转区给力了。
不知道美亚可否邮件推送,还是否能用原来加密格式的书,还是否能同步中亚买的书
文章已发布,详见《Kindle 退出中国后如何继续购买电子书及使用推送服务》。
批量下载可以使用这个油猴脚本:https://greasyfork.org/zh-CN/scripts/445943
但是这个脚本应用的网址为 https://www.amazon.cn/gp/digital/fiona/manage,我已经在 GitHub 提交了 PR 增加 https://z.cn/myk 所指向的地址的匹配,但不确定原作者是否会合并以及何时合并。自己临时增加可以在油猴脚本用户匹配设置里增加“https://www.amazon.cn/mn/dcw/myx.html*”,或者直接用脚本原本支持的那个地址。
更新:作者已经合并更新了
请教一下,Calibre 和 DeDRM都装好了,序列号也输入了,但是转换的时候还是提示受到保护,是哪里没对呢?我安装完插件,输入序列号都重启 Calibre 的啊,然后再导入的图书。
依次检查:序列号属于下载电子书时所选择的 Kindle 设备的;序列号是点击插件设置中的【eInk Kindle ebooks】按钮后填写的;填写的序列号是正确的(注意容易和数字混淆的字母)。
另外,插件设置好后,电子书拖放进 Calibre 就已经完成了 DRM 的移除,不需要额外的格式转换,除非你需要其它格式。
问题解决了,我之前用的分叉版插件,后来装回原始版本就可以了。
也遇到相同的问题了!
自动下载的功能非常好!但是导入Calubre后无法完成DRM的移除。采用手动下载后电子书可以移除DRM的。
所以,问题是如何能解决自动下载时遇到的问题。
谢谢!
按说自动下载和手动下载时没区别的,都是通过点击下载链接下载的。
一种可能是是文件下载不完整导致的,你可以检查一下那个自动下载的无法移除 DRM 的电子书文件,和手动下载的文件大小对比一下,看是否一致。另外,可以尝试将无法去除 DRM 文件拷贝到 Kindle 中,看 Kindle 能否直接打开。
对比了几个文件的大小,没有异常。手动下载时有选择kindle设备的,不知道脚本下载时是否有选择kindle设备。本人同时注册有多个设备。不知道这是否是引起不能移除DRM的原因。后续我再试一下,把全部设备的系列号都在DEDRM上注入。谢谢!
脚本使用的是默认选择的 Kindle 设备。如果有多台 Kindle 设备,不确定下载的电子书用的是哪一台,可以将它们的序列号都添加到 DeDRM 的设置中。
十分感谢!我将全部kindle设备的系列号都录入dedrm后,自动脚本下载的电子书都成功解除DRM了。谢谢!
感觉个人文档才是重灾区……我的文件都还在,但大部分中国账号可以正常推送的mobi和epub都无法传到日亚和美亚,中文书日文书下载的自制的都有,范围太大了根本排查不了问题出在哪里。想知道有没有遇到同样问题的朋友,你们做了哪些尝试呢?
好多传了没反应
我测试发现azw pdf txt都正常,但绝大多数书都是mobi和epub格式,几乎都中招了。解决不了的话以后就只能装插件用自己的邮箱推,但这样就不能多端同步了。
我的都在个人文档可以下载下来吗
亚马逊没有像电子书那样为个人文档提供下载链接,只能通过 Kindle 下载。
有批量下载的方法吗?
批量下载JS脚本:https://gist.github.com/yushiro/108414f000a08c456c546c662de177c5