
KindleUnpack:拆解 Kindle 电子书文件的利器
在之前修复 Kindle 字典释义显示不完整的那篇文章里,曾提到 KindleUnpack 这款小软件,在文章中,主要是用它来“拆解” mobi 格式的字典文件,提取里面的相关源文件,以便进行分析、修改。最近 Kindle 伴侣 QQ 群中有小伙伴说网站还没有关于 KindleUnpack 的相关文章,所以书伴就专门撰写一篇文章来介绍一下,并同时将其放到“相关工具”中提供下载。

目录
一、什么是 KindleUnpack?有什么用?
二、KindleUnpack 软件或插件下载
三、KindleUnpack 插件版本的安装
方式 1:“从文件加载插件”安装
方式 2:“获取新的插件”安装
四、KindleUnpack 各版本的使用方法
1、Windows 界面版
2、macOS 界面版
3、Calibre 插件版
五、KindleUnpack 提取出的文件结构
六、KindleUnpack 批量处理命令
一、什么是 KindleUnpack?有什么用?
KindleUnpack (原 mobiunpack)是一款用 Python 写成的小程序,始发于电子书专业论坛 mobileread。它可以用来提取 Kindle 电子书如 mobi、azw3 等格式文件中的 HTML 内容、图像以及元数据文件,并能把这些文件按照 KindleGen 生成电子书的标准和形式放置。
对于 KF8 文件以及 Mobi 和 KF8 的混合文件[注1],它可以产生分离的 Mobi 和 KF8 文件[注2],以及包含在电子书中的原始源文件。此外,对于 KF8 文件,它还会生成一份 ePub 文件,不过,如果生成的 HTML 文件不符合 EPUB 标准,那生成的这个 ePub 文件也不会符合 EPUB 标准。对于亚马逊 .azw4 格式电子书,它可以提取出包含在该格式文件中的 PDF 文档。
KindleUnpack 对于一般人来说没有什么用途,但是对于喜欢自制电子书的小伙伴用途可就大了。比如看到一本电子书的版式或样式很漂亮,可以利用它对这本电子书进行拆解,然后分析其源文件,然后把自己喜欢的特性移植到自己的电子书项目中。是一个相当实用学习工具。
二、KindleUnpack 软件或插件下载
KindleUnpack 有两个版本,一种带界面的,另一种依附于 Calibre 插件运行的。界面版分为两种,带界面的 pyw 格式 Python 脚本和在 macOS 系统中支持拖放操作的 AppleScript 版本。
另外,作者还提供了一个可在命令行中使用的的单文件脚本[注3] mobiunpack,该脚本仅支持提取 Kindle 早期的 MOBI7 格式或更低版本的电子书源文件,无法用于 KF8 标准的电子书。
下面是 KindleUnpack 项目及其 Calibre 插件发布地址,可以在这里获取最新版本:
- KindleUnpack 项目发布地址:Github 发布页面
- Calibre 插件发布地址:Github 发布页面
下面是 KindleUnpack 各个版本的下载链接,请根据自己所使用的系统选择下载:
- 带界面的 pyw 格式 Python 脚本: KindleUnpack-081.zip | 百度网盘〈提取码:
qb7i〉 - 支持拖放操作的 Mac 版本(64 位):KindleUnpack 64 v0.81.app.zip | 百度网盘〈提取码:
b35g〉 - 支持拖放操作的 Mac 版本:KindleUnpack v0.81.app.zip | 百度网盘〈提取码:
qpza〉 - 仅支持 mobi 文件的单文件脚本:mobiunpack 32.py.zip | 百度网盘〈提取码:
rhbz〉 - 依附于 Calibre 运行的插件版本:kindle_unpack_v0831_plugin.zip | 百度网盘〈提取码:
1nxt〉
需要注意,界面版 KindleUnpack 需要你的系统预先安装 Python。一般情况下 Mac 或 Linux 系统已经集成了所需要的 Python 环境,不需要额外进行安装。但是 Windows 则需要额外安装 Python 环境,作者强烈建议 Windows 用户安装 ActiveState 的 Active Python 2.7.x 版本,它可以正确安装和配置必要的部件,而 Python 官方版本可能不能在 Windows 系统中正确的处理这些事情。
三、KindleUnpack 插件版本的安装
如果你习惯喜用 Calibre 管理电子书,可以直接把 KindleUnpack 集成到 Calibre 中,这样就不需要每次都运行起带界面的程序了。在 Calibre 中安装 KindleUnpack 插件有两种方式:一种是直接加载下载到的插件文件,另一种就是直接在插件设置中获取该插件直接安装。下面分别作说明:
方式 1:“从文件加载插件”安装
打开 Calibre,点击“首选项”的“高级选项”下的【插件】,然后点击【从文件加载插件】按钮,在弹出的窗口中选择下载到的压缩包,点击【是】、【确定】,重启 Calibre 完成安装。
方式 2:“获取新的插件”安装
打开 Calibre,点击“首选项”的“高级选项”下的【插件】,然后点击【获取新的插件】,在弹出的窗口中的“Filter by name(按名称过滤)”一栏输入“KindleUnpack”,选中它,点击右下角的【安装】按钮安装。安装完毕后点击【现在重启 Calibre】按钮,重启后即可成功安装。
四、KindleUnpack 各版本的使用方法
KindleUnpack 的使用方法十分简单,下面对界面版和插件版分别简要说明一下步骤,以供参考。
1、Windows 界面版
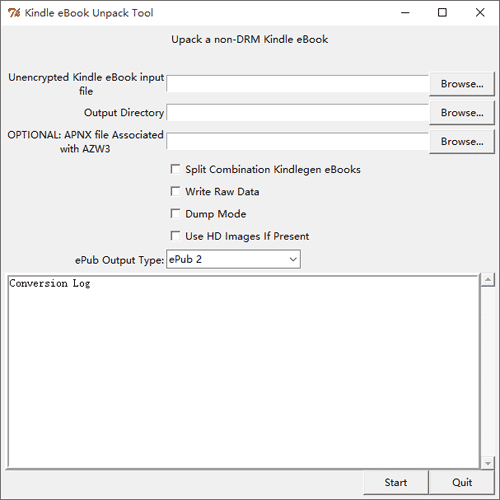
- 运行文件名为 KindleUnpack.pyw 的 Python 脚本,打开工作界面;
- 点击“Unencrypted Kindle eBook input file”后的【browse…】按钮选择一本电子书;
- 点击“Output Directory”后的【browse…】按钮选择生成文件的输出目录;
- 其他选项一般可保持默认,点击【start】按钮,稍等片刻即可完成拆解。
2、macOS 界面版
解压缩下载到的 zip 压缩包,可以看到一个 APP 文件,直接把电子书拖放到此 APP 图标上即可。
3、Calibre 插件版
- 把电子书文件拖放到 Calibre 中;
- 选中电子书,点击软件右上方操控区域的那个 KindleUnpack(黄色的三角按钮图标),在弹出的菜单中将鼠标悬浮到带有绿色小锁的菜单,然后点击弹出的菜单“Unpack MOBI”(如果是 AZW3 文件会显示“Unpack AZW3”);
- 在弹出的窗口中选择指定输出的文件夹,点击【Open】按钮,稍等片刻即可完成拆解。
注意,KindleUnpack 只能用于无 DRM 保护的 Kindle 电子书。生成的时间根据电子书文件大小不同,处理时间长短也不同。
五、KindleUnpack 提取出的文件结构
对于 KF8 标准的如 azw3 格式的电子书,提取出来的原始文件结构一般如下所示:
├──── HDImages
├──── 高清图片文件(如果有的话)
├──── mobi7
├──── 所有图片(包括封面)
├──── mobi8
├──── META-INF
├──── container.xml
├──── OEBPS
├──── Fonts
├──── 字体文件(如果有的话)
├──── Images
├──── 所有图片(包括封面)
├──── Styles
├──── 所有 CSS 样式表文件
├──── Text
├──── 所有 HTML 格式的电子书内容
├──── content.opf
├──── toc.ncx
├──── XXXXXX.epub
├──── mimetype
对于 mobi 格式的电子书,提取出来的原始文件结构如下所示:
├──── HDImages
├──── High definition images if exist ...
├──── mobi7
├──── Images
├──── 所有图片(包括封面)
├──── book.html
├──── content.opf
├──── toc.ncx
六、KindleUnpack 批量处理命令
首先确保你的操作系统安装了 Python,并且已经下载好了 KindleUnpack 压缩包。
这里假设 KindleUnpack 文件夹(比如这里解压后得到的是 KindleUnpack-083)和存放电子书的名为 ebooks 的文件夹都存放在桌面上,比如 C:\Users\YOURNAME\Desktop(注意要将 YOURNANE 更改成你实际的系统用户名)。
如果你用的是 Windows 系统,打开 PowerShell,运行以下命令:
Set-Location C:\Users\YOURNAME\Desktop; Get-ChildItem ebooks | % { python3 KindleUnpack-083\lib\kindleunpack.py $_.FullName }如果你用的是 macOS 系统,打开终端,运行以下命令:
cd /Users/YOURNAME/Desktop; for file in ebooks/*; do python3 KindleUnpack-083\lib\kindleunpack.py "$file"; done参考资料:
- KindleUnpack (MobiUnpack): Extracts text, images and metadata from Kindle/Mobi files
- [GUI Plugin] KindleUnpack – The Plugin
- [注1] KF8 是亚马逊官方制定的新电子书标准,能很好地支持 CSS3 的很多属性,以获得更好的排版样式。我们平常经常见到的 azw3 文件就是标准的 KF8 标准电子书。因为老的 Kindle 设备不支持新标准,所以亚马逊会将老式的 mobi 格式混合在 azw3 文件内,以便兼容老的 Kindle 设备。
- [注2] 这里的 mobi 文件和 KF8 文件实际上说的是一个标准,实际上分离出来文件,mobi 对应的就是 mobi7,KF8 对应的就是 mobi8。
- [注3] KindleUnpack 0.61 就是由 mobiunpack 0.32 变化而来的。
© 「书伴」原创文章,转载请注明出处及原文链接:https://bookfere.com/post/187.html
延伸阅读
- Kindle 固件降级教程:支持部分已越狱 Kindle 设备
- [2016.08.04] Kindle 阅读器固件升级至 5.8.2
- 亚马逊尊贵版 Kindle Oasis 令人不快的五点缺陷
- macOS 版 Send to Kindle 新增 USB File Manager 应用
- [每周一书]《贪婪的多巴胺》驱动爱、性和创造力
- Windows 10 周年更新后连接 Kindle 蓝屏问题
- Kindle 漫画制作软件 ChainLP 简明教程
- [2017.05.16] Kindle 阅读器固件升级至 5.8.9.2
- 罗斯高:农村儿童的发展怎样影响未来中国
- [2015.02.20] Kindle 阅读器系列产品固件升级
- [2018.05.01] Kindle 阅读器固件升级至 5.9.5.1
- 再续经典!第三代 Kindle Paperwhite 评测
- [2025.08.19] Kindle 阅读器固件升级至 5.18.4.0.1
- 爱范儿:亚马逊 Kindle Oasis 2017 款评测
- [每周一书]《规模》用宏观思维看世界变化
通过 Google 搜到了这篇文章,按方法解决了我的 azw3 → epub 问题,到此一游顺便点个赞 👍👍👍
最近日亚下载的书从azw3变成了azw,好多工具都已经失效了,想问问现在的提取方法是什么呢?
我下载了一些以图片为主的azw文件,想尝试打印出来,但无论如何只要把它转换成pdf,排版就会变乱,图片会变形,我试着用这个插件确实可以把图片全部提取出来,但是我要打印的话,除非自己用这些图片再按照azw的排版重新制作一本电子书,否则还是无法获得一份完美的pdf,不知道怎样才能把azw按照原本的排版完美的转换成pdf。
你可以尝试用网页浏览器(如 Chrome)打开拆解出来的 XHTML 文件,然后用浏览器的打印功能将其打印成 PDF 文件,应该能保持原来的排版。
我查看了一下xhtml文件,一本书解开后会有很多个这种文件,只能挨个打印,无法变成有多页的PDF文件。这个问题我研究了一下,发现归根结底是在于azw/epub/mobi这几种格式和PDF格式在根本上是不同的,这些格式都属于电子书文件,是针对电子屏幕设计的格式,而PDF格式是针对打印输出的格式,PDF格式无法编辑,或者说编辑起来很困难,是因为他每一个元素的位置、大小、样式都是固定死了的,这样在所有的设备上查看起来都是一个样子的,打印出来也是跟在电脑屏幕上看到的一模一样,所以用kindle这类小屏幕的设备看PDF就会字很小,如果要正常查看,必须重排版。PDF文件的页数,每一页多少行,每行多少字是固定不变的,打印出来自然就十分美观,电脑上无论什么文件点击打印后都会生成一个PDF发送到打印机。
而相反,azw/epub/mobi文件则是没有固定的页数,每一个多少行,每行多少字都是不固定的,这些格式就类似网页,一个很长的网页你说他有多少页,说不出来,因为这个取决于屏幕的大小,屏幕越大,每一屏(页)显示的内容就越多,页数就更少,每一行有多少字,取决于屏幕宽度,在不同的设备上打开这类文件,他都会实时重新排版以适应屏幕,PDF格式则是无论如何都保持一样的排版,不会重排版。
所以结论就是,如果是纯文本的电子书,转换成PDF格式重新排版是很容易的,无非是每一页的行数和字数变一下。但我需要将一些全是图片的电子书变成PDF,排版就一定会乱,因为图片有大有小,在电子屏幕上查看,无论大小都可以自动缩放以适应屏幕显示,但转成PDF格式之后,图片不会自动缩放,就会造成一张大图片会被分到两页显示,每一页只有半张图,这就没法看了。要想将这类电子书完美的转成PDF格式,用任何自动转换软件都无法实现,只能将电子书拆解开之后,用排版软件将图片放进去,手工排版。azw/epub/mobi生来就是为电子屏幕显示的, 他就不是针对打印设计的,强行将其打印出来,只能是强人所难,无法实现。
你好,calibre v6.25版本,安装插件后右上角没有相关按钮,是否已经不可用了?
下载了windows界面版也全部Unpacking Failed了
简单写了一个使用KindleUnpack批量处理电子书的powershell脚本(Windows平台),有需要的朋友可以拿来修改一下使用:https://gist.github.com/chthollyphile/6de97cb97e944e96c08a7df9ba46369c
站长知道有什么工具可以批量unpack吗?中亚买的书比较多,一本一本点太麻烦了。
如果你熟悉命令行工具,可以通过“终端”或“命令提示符”实现批量处理。如果想要界面版的,好像没有现成的。如果你对前者有兴趣,我可以告诉你怎么做。如果只喜欢带界面的,书伴有打算给 KindleUnpack 写一个带批量处理功能的界面,你需要等等。
我有兴趣,能请告诉我怎么用命令批量处理吗?谢谢。
首先确保你的操作系统安装了 Python,并且已经下载好了 KindleUnpack 压缩包。
这里假设 KindleUnpack 文件夹(比如这里解压后得到的是 KindleUnpack-083)和存放电子书的名为 ebooks 的文件夹都存放在桌面上,比如 C:\Users\YOURNAME\Desktop(注意要将 YOURNANE 更改成你实际的系统用户名)。
如果你用的是 Windows 系统,打开 PowerShell,运行以下命令:
如果你用的是 macOS 系统,打开终端,运行以下命令:
成功了,太谢谢了!!
你好,不好意思,再问一下,请问,有没有办法只提取图片,不要其他的呢?
请问怎么在Mac怎么批量把mobi转为epub?
将其中的
python3 KindleUnpack-083\lib\kindleunpack.py改为你要用的转换程序即可。mac 2020air 下载了64位的kindleunpack,但是拖拽文件到app上没有反应,也没有新的电子书出来。。不知道为啥
救命,它没有显示重启按钮,我找不到重启安键
我用的是Calibre便携版
可以手动退出再开启 Calibre 试试。
但还是
calibre, version 5.26.0
错误: 必须重启: 你必须先重启 calibre 后才能配置 KindleUnpack – The Plugin 插件
这句话
再试试通过菜单【首选项 → 以调试模式重启】,打开后,手动退出再重新启动 Calibre。
我用第二种方法成功啦!
谢谢!
插件装入calibre了,但是重启之后还是没有显示呀,怎么回事呢?
Calibre 是哪个版本,安装的插件是哪个版本?
站长老师,这个软件在2.7脚本上打不开,3.9脚本下能打开,但是没法解包,每次都是解包失败。
可以安装最新版本的 KindleUnpack 再试试看。还不行的话,推荐用 Calibre 插件。
Input Path = “D:\電子書籍(繁體竪排).mobi\言情小說\瓊瑤\《白狐》.mobi”
Output Path = “E:\迅雷下载\KindleUnpack-081”
Epub Output Type Set To: ePub 2
Please Wait …
Error: Unpacking Failed
总是解包失败,这个软件不能用了