
如何把 MDX 格式词典转换成 MOBI 格式的 Kindle 字典

注意,本文提供的方法某些步骤依赖 Windows 系统,如你使用的是其它系统(如 macOS),可参考《PyGlossary:将其它格式的字典转换成 Kindle 字典》这篇文章提供的跨平台解决方案。
目前 Kindle 字典资源(尤其是小语种字典)还不算太丰富,其来源除了亚马逊官方为 Kindle 提供的一些字典外,就是第三方机构制作或网友自制的字典了。而网友自制的字典,大部分都是通过其它字典格式转换而来,毕竟除非是专业从事制作字典工作的,手工录入词条不太现实。
本文要介绍的便是转换 Kindle 字典的一种方法,即把 MDX 格式的词典转换成适用于 Kindle 的 MOBI 格式字典。MDX 也是一种字典格式,而且相比 Kindle 的 MOBI 格式字典,资源更为丰富一些,你可以通过相关的资源站点(如PDAWIKI、星际译王词库、OwnDict)下载 MDX 词典资源,也可以通过搜索引擎搜索“mdx词典”寻找 MDX 词典资源。本文同样适用于 StarDict 字典的转换。
只要你有 MDX 词典文件或其源文件(包含 dict、idx 和 ifo 三个文件),就可以通过下面的方法将其转化成 Kindle 字典。感谢 Kindle 伴侣交流 QQ 群(一群)的小伙伴 @汪星人 提供的转换步骤,以下内容便是以此为蓝本修缮而成。本教程仅适用于 Windows 系统。
一、准备工作
转换过程中需要用到以下软件,请点击链接下载备用。
- GetDict.exe:百度网盘 * 转换 StarDict 字典可不下载
- python:官方下载 * 请安装 2.7.x 版本,如果系统已安装请忽略
- tab2opf.py:百度网盘【提取码:
7eib】 - mobigen.exe:百度网盘
- StarDict:百度网盘
二、转换步骤
下面以 MDX 格式的“牛津高阶英语词典(第8版)”举例说明(你也可以使用自己下载到的 MDX 词典文件),详细演示如何一步一步地将其转换成 MOBI 格式的 Kindle 字典。
1、将 MDX 字典转换成 MDX 源文件
运行程序 GetDict.exe。在“选择MDX词典”这项中,点击【浏览…】选择准备好的 MDX 文件,如“牛津高阶英语词典(第8版).mdx”;在“转出文件”这项中,点击【浏览…】选择字典源文件输出路径,建议新建一个文件夹,如“oa8”,输入文件名,如“oa8”,点击【保存】按钮;其它选项保持默认,点击【开始转化】按钮,在弹出的对话框“词典名称”中输入词典的名称,如“oa8”,点击【确定】按钮开始转换。
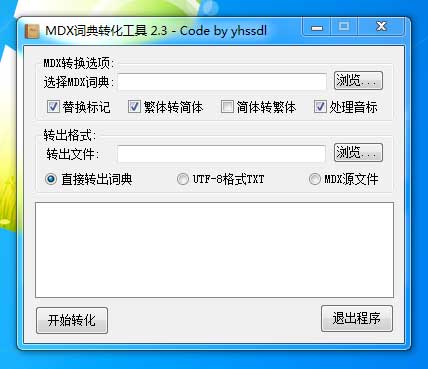
转换完毕后,在“oa8”这个文件夹中会出现 oa8.dict、oa8.idx 和 oa8.ifo 三个文件。
注意,如果你下载到 MDX 词典本身就是源文件的形式,则可以忽略上面的步骤。不过如果遇到词典源文件后缀为 .dict 的文件后还有一个 .dz,如“***.dict.dz”,需要将 dz 重命名为 gz,并用 7-zip 软件解压,得到“***.dict”文件,然后将后缀名为 .dict 的文件名重命名一下,和其他两个文件的文件名统一起来。
2、将 MDX 字典转换成 TXT 文件
解压缩下载到的“StarDict.zip”,运行文件夹里的“stardict-editor.exe”,切换到“DeCompile/Verify”标签,点击【browse…】按钮,选择“oa8”文件夹中的后缀名为 .ifo 的文件。然后点击【Decompile】按钮,稍候片刻。直到出现提示信息“Done!”,即表示转换成功。
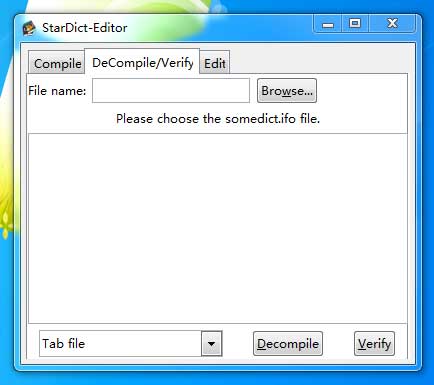
此时“oa8”文件夹中会出现一个转换得到的名为“oa8.txt”的文本文档。
建议检查一下这个文档的内容是否显示正常,如果出现了乱码,请将其更改成正确的编码再保存。否则,后面转换字典文件时出现类似“Source file is not valid UTF8.”的错误提示。
3、将 TXT 文件 转换成 MOBI 源文件
把 tab2opf.py 拷贝到“oa8”文件夹内。打开“命令提示符”,并用 cd 命令切换到“oa8”目录下,输入以下命令(如果已将 python 添加到环境变量则无需输入 python 的全路径):
C:\python27\python.exe tab2opf.py -utf oa8.txt等待命令运行完毕之后,在“oa8”文件夹下会出现一个 .opf 文件和几个 .html 文件。用记事本或代码编辑器打开其中的 .opf 文件,然后找到如下所示这段代码:
<metadata>
<dc-metadata>
<dc:Title><h2>oa8</h2></dc:Title>
<dc:Language>en</dc:Language>
<dc:Identifier id="uid">oa8</dc:Identifier>
</dc-metadata>
<x-metadata>
<DictionaryInLanguage>en-us</DictionaryInLanguage>
<DictionaryOutLanguage>en-us</DictionaryOutLanguage>
</x-metadata>
</metadata>请按照下面的提示说明(红色字符部分)修改上面所示代码:
<dc:Title><h2>词典的名字</h2></dc:Title>
<dc:Language>词典的语言</dc:Language>
<DictionaryInLanguage>输入的语言</DictionaryInLanguage>
<DictionaryOutLanguage>输出的语言</DictionaryOutLanguage>
其中“词典的名字”即是 Kindle 字典的正式名称,如本例中可将其修改为“牛津高阶英语词典(第8版)”。词典的语言一般不用修改,关键在于输入和输出的语言。如果是英汉词典,输入为英语 en-us,输出为汉语 zh;同理,如果是日中词典,则输入为日语 ja,输出为汉语 zh。
* 提示:language 标签中的“语言代码”需符合 RFC5646 标准(来源),如 en、zh-CN,DictionaryInLanguage 和 DictionaryOutLanguage 标签中的“语言代码”需符合 ISO 639-1 标准(来源),如 en,可附加区域性代码,如 en-us。
修改完毕后,另存为,文件名不要改动,在“编码”选项中选择“UTF-8”,然后点击【保存】按钮。
* 提示:在此步骤中使用 tab2opf.py 进行转换可能存在变形词无法识别、词典过大的问题,为达到更好的转换效果,Windows 用户可以尝试网友开发的转换软件 MDictindle。
4、将 MOBI 源文件转换成 MOBI 文件
把 mobigen.exe 拷贝到“oa8”文件夹内。把刚才生成的那个 .opf 文件拖放到 mobigen.exe 文件上,mobigen.exe 就开始将 MOBI 源文件转换成 MOBI 文件了,转换所需时长根据字典大小而有所不同。
最终得到的 MOBI 格式文件就是转换好的字典文件了。将其拷贝到 Kindle 中即可使用。
注意,在转换的过程中会出现类似“Warning(prcgen):Some syntax error happend in a script …”或“Error: Unexpected token found”之类的提示,这是因为源文件中有一些 javascript 脚本,在转化的过程中被 mobigen 忽略掉了。经过测试不影响最终生成字典文件的使用。
三、已知问题
通过此方法转换的字典,其查询是严格匹配,不支持模糊检索,所以会导致单词变形无法匹配。
© 「书伴」原创文章,转载请注明出处及原文链接:https://bookfere.com/post/308.html
延伸阅读
- Sigil 基础教程(二):Sigil 的基本操作
- 新第 11 代入门版 Kindle 泄露出更多详情,包括多款儿童版
- 杨绛谈读书:乐在其中,读书好比串门儿
- [每周一书]《债务危机》我的经验和应对原则
- 入门版 Kindle 12 愿望清单:所有我希望看到的新特色
- [每周一书]《支配与抵抗艺术》无权者与有权者之间的对抗
- [网友投稿] 多看未root下增加罕见生僻字及替换系统字体
- 外出旅行时如何用安卓手机推送电子书到 Kindle
- Kindle 固件版本号查询方法及固件更新步骤
- 东方魔幻《鬼吹灯》Kindle 电子书全集
- 我从未喜欢过电子书阅读器,但 Kindle 应用改变了我
- [每周一书]《创业维艰》创业的心路和经验之谈
- Kindle Oasis 开售:薄得惊人,贵得可怕
- GitBook 制作 Kindle 电子书详细教程(可视化版)
- [每周一书]《写给无神论者》信仰到底有什么用
第二步的时候就报错了 不知道如何进行下去
请问没有出现 .opf 文件,怎么回事?
Building…
[critical] Error, file version is not 2.4.2.
Done!
请问,我的ifo显示版本为3.0.0,该怎么转txt呢
CvtStarDict2Txt可以分解
https://www.pdawiki.com/forum/thread-843-1-1.html这里可以下载
有的电子词典是mdx+mdd两个文件组成(mdx存储文字基本信息,mdd存储图片),请问这种类型的有办法转为mobi词典吗
请教一下,mdx格式的字典可以直接用在kindle上面吗?
不能,因此才需要转换。
书伴您好:已按教程完成字典转换,但又些字符显示不出来,字典已发您邮箱[email protected],请您帮忙检查,感谢!