
Calibre 使用教程之抓取 RSS 制成电子书
之前 Kindle 伴侣曾经写过一篇文章——在 Google App Engine 上用 KindleEar 搭建 RSS 推送服务器,架设成功后可以添加你所喜欢的 RSS 订阅源,KindleEar 就可以自动抓取最新文章,并以期刊的形式定时推送到你的 Kindle 中。那除此之外,有没有其他抓取 RSS 订阅源的方法?当然有!Calibre 自身就带有 RSS 抓取功能模块,KindleEar 便是采用的该模块为基础写成的。虽然 Calibre 带有命令行的操作方式,但对于普通用户来讲不怎么友好,所以本文仅以界面操作方式为例作说明。
一、准备订阅源
RSS 订阅地址五花八门没有一定的规律,所以获取 RSS 地址的方法也不尽相同。一般提供 RSS 订阅的站点都会提供一个 RSS 图标,点开就可以得到该站点的 RSS 订阅地址。如果页面上没有此图标,可以查看一下网页的源代码,找到 <link rel="alternate" type="application/rss+xml" title="<title>" href="<url>" /> 这样的行,其中的 <url> 就是 RSS 地址。另外还有一些浏览器如 Firefox、Opera 会自动获取网站的 RSS 订阅地址,并在地址栏上标示小 RSS 图标,也能方便地获取该站点的 RSS 地址。
二、添加订阅源
准备好 RSS 订阅源后,就可以在 Calibre 中添加这些订阅源了。打开 Calibre,在 Calibre 主界面上方的功能图标中找到“抓取新闻”,点击右侧的向下箭头,在弹出的菜单中点“添加自定义新闻源”。
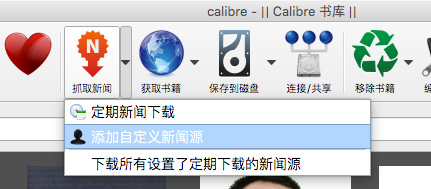
在弹出的对话框中,点击【New recipe】按钮,切换到“添加自定义新闻来源”对话框。在“订阅清单标题”中输入一个名字,比如“我的订阅”(这个名字是一个分类名,其下将会包含一组 RSS 订阅地址)。
“最老文章”可以设置抓取文章的时效性,默认情况下,Calibre 只会抓取最近 7 天的文章,如果想要抓取更多,可以自定更改天数。“每个源的最多文章数”可以设置抓取文章的数量上限。不过需要注意的是,这两项设置都受限于网站 RSS 的输出方式,比如有些网站的 RSS 只输出数量有限的最新几篇文章,所以不管在 Calibre 中怎么设置,都受此限制,不一定能获取到指定数量的文章;
接下来,需要在“将新闻加入订阅”中添加我们准保好的 RSS 地址。在“源名称”中也输入 RSS 订阅的名字,比如“Kindle伴侣”;然后再“源网址”中输入 RSS 地址,如“https://bookfere.com/feed”;最后点击【添加源】按钮,就可以把一条 RSS 订阅添加到“订阅清单中的新闻”中了。在一个订阅清单中可以抓取多个 RSS 源,所以可以重复操作输入多个 RSS 源名称和源网址并多次添加。
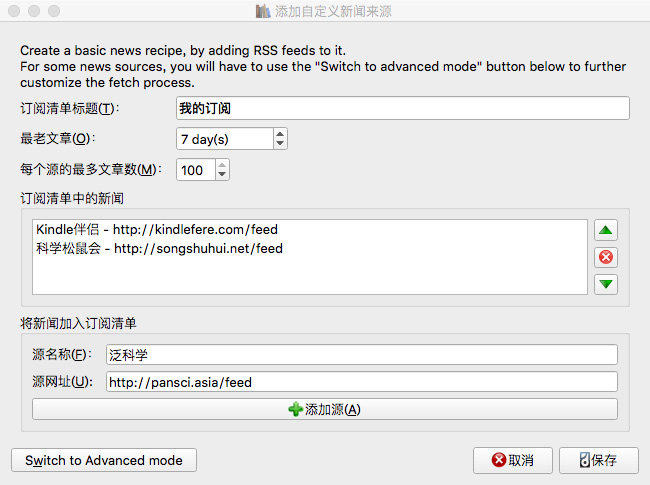
添加完成 RSS 订阅地址后。点击右下角的【保存】按钮保存,返回到“添加自定义新闻源”界面。如果需要修改,可以在左侧列表选中一个项目,然后点击【Edit this recipe】按钮修改。如果想要修改,则点击【Remove this recipe】按钮删除。没什么问题的话可以点击【关闭】按钮返回 Calibre 主界面。
三、抓取并推送
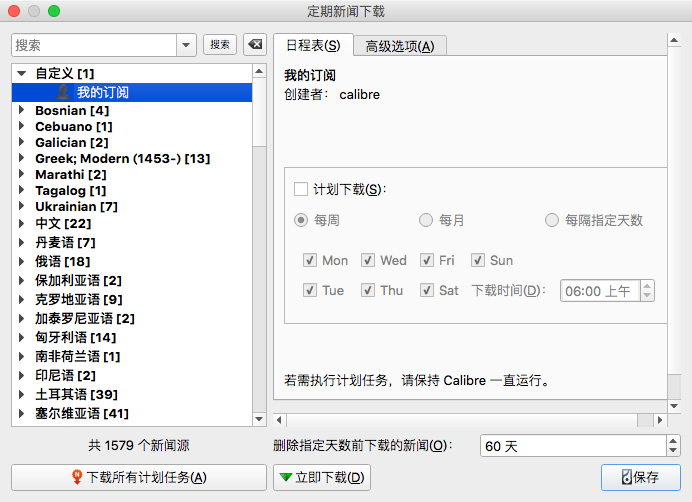
设置好订阅源后就可以抓取新闻了。同样,在 Calibre 主界面上方的功能图标中找到“抓取新闻”,点击它,会弹出一个“定期新闻下载”的对话框。在左侧列表中找到“自定义”分类,点击展开,就可以找到你刚刚添加的订阅清单,选中后点界面下方的【立即下载】按钮,Calibre 便会开始抓取 RSS 内容。
抓取成功后,Calibre 会生成一本期刊格式的电子书并自动存放到书库中。如果你设置了邮件推送,Calibre 还会把生成好的电子书自动推送到云端,以便自动同步到你的 Kindle 中。

当然,除了这种手动抓取的方式外,还可以通过“计划下载”定时抓取,比如按每周、每月或每隔指定天数抓取 RSS 内容,不过前提是你得一直开着电脑并保持电脑的联网状态。
另外还需要注意,有些网站的 RSS 仅输出摘要,这样 Calibre 也只能抓取到摘要内容;还有就是如果你订阅的 RSS 被墙了,并且你的网络没有使用代理的话,将无法成功抓取。
如果你需要抓取的网站没有提供 RSS 供稿,可以参考《Calibre 使用教程之抓取网站页面制成电子书》这一篇文章提供的方法,编写脚本直接抓取网站的页面内容并制成电子书。
© 「书伴」原创文章,转载请注明出处及原文链接:https://bookfere.com/post/256.html
“制作Kindle电子书”相关阅读
- 乐书:在线 Kindle 电子书制作和转换工具
- Kindle Comic Converter:最简单的漫画转换工具
- Sigil 基础教程(二):Sigil 的基本操作
- 遵循亚马逊标准!Kindle 电子书专业制作教程
- 如何给自制 Kindle 电子书添加弹出脚注或尾注
- 制作 KF8 标准电子书示例(上):字体与文本
- GitBook 制作 Kindle 电子书详细教程(可视化版)
- Kindle Comic Creator:亚马逊官方漫画转换工具
- 如何更改阿拉伯语、维吾尔语电子书的文字方向
- Calibre 使用教程之抓取网站页面制成电子书
- 亚马逊 Kindle 电子书发布指南(二)一般最佳实践
- Sigil 进阶教程:从零开始制作 EPub 电子书
- Sigil 基础教程(一):EPub 格式介绍
- 亚马逊 Kindle 电子书发布指南(三)特定类型电子书指南
- GitBook 制作 Kindle 电子书详细教程(命令行版)
你们好,这块我有几个问题想请问一下:第一个是我从网站上的源代码里找RSS订阅地址,没有找到本文提到的那行语句,请问这是什么原因,是不是所有的网站都会有RSS订阅地址;第二是在calibre的‘抓取新闻’中我看也有很多新闻源,那这些是不是下载后也可以推送到kindle上?感觉下载速度很慢,有没有解决办法;第三是我设置好了电子邮件推送到kindle,是不是它每次下载来只是保存在calibre的书库,要到kindle上看,还需要打开calibre,点里面的‘连接/共享’发送过去才行?另外,保持calibre一直运行,是不是就是不能关电脑了?谢谢。
并非是每个网站都提供 RSS 供稿;Calibre 内置的新闻源大多可以抓取,但是大多需要翻墙;新闻下载成功后会存放在 Calibre 书库,同时通过你设置的邮箱推送到你的 Kindle 上;如果你想要定时抓取新闻,就需要确保 Calibre 一直运行且网络通畅。
好的,几个问题我都了解到了,非常感谢你们的回复。谢谢😀
还想请问下该怎么设置自动推送啊 自动下载我是搞好了的 然后推送服务器什么的也设置好了 但是我找了半天也没有自动推送的选项
Calibre 的抓取新闻功能下载后就会自动推送,应该是不需要额外设置的。
代码中设__author__= xxx无效,得到的作者都是calibre 很影响刮削
抓取的新闻好像不能使用自定义字体 我看的日语新闻却使用的是简体中文的字体非常难受 有什么方法解决吗
Calibre 抓取新闻转换的是 MOBI7 格式,不支持自定义字体,除非另行将其转换成 MOBI8 格式。
calibre抓取的新闻只能是mobi格式吗?如果不想在kindle上面看,想用ipad看怎么办呢?因为有的杂志图片很多的确实不适合kindle看。
Calibre 的界面版“抓取新闻”不支持输出为其它格式。这里提供三种变通的解决方法:
1、去 App Store 下载 Kindle 应用,绑定亚马逊账号后,用邮箱把 MOBI 文件推送到应用中阅读。
2、抓取新闻获得 MOBI 文件后,用 Calibre 将其重新转换成包括 EPUB 在内的其它你需要的格式。
3、使用 Calibre 提供的命令行工具可将新闻直接输出为包括 EPUB 在内任一格式。具体可参考这里。
抓取的rss怎么自定义封面?
如果你是通过本文介绍的方法抓取新闻的,需要在抓取脚本中指定封面路径。
具体方法为:在 Calibre 界面上找到“抓取新闻”按钮,点击它旁边的倒三角,在弹出的菜单中点击“添加自定义新闻来源”,选中你自定义的脚本并点击【编辑订阅清单】按钮,在脚本代码中添加如下属性定义(可以在已存在的属性
masthead_url下一行添加):注意,其中的
/path/to/cover.jpg要换成真实图片的绝对路径,如果你使用的是 Windows 路径需要加上盘符,如D:\path\to\cover.jpg。当然你可以添加一个图片网址,如http://example.com/path/to/cover.jpg。非常感谢您的回复,还有一个问题,recipe 抓下来之后会制作成mobi7格式的mobi,有没有办法输出成mobi8格式,谢谢~!
期刊样式的 MOBI 只支持 MOBI7,如果你不在乎期刊样式,可以将其转换成 MOBI8。
具体方法为,将脚本代码保存为 .recipe 格式的文件并拖放到 Calibre 书库中,然后像转换普通电子书那样转换成你想要的格式。另一种方法是,使用 Calibre 的命令行工具 ebook-convert 转换 .recipe 文件,具体用法参考《Calibre 常用命令行工具详解之 ebook-convert》这篇文章。
如果用ebook-convert的,被抓的网站需要登陆这里怎么处理?就像如下这一段脚本:
如果用GUI的话,会有一个用户名及密码输入框,抓取很正常,但如果改成命令行的话怎么写?非常感谢!
你需要在 Recipe 脚本中重写 get_browser() 函数,具体可参考官方代码库中的 news.py 这个文件中关于该函数的注释。
请问怎么设置抓取rss默认输出awz3格式?另外,怎么设置抓取的rss默认语言是英文?比如抓取一些双语文章时,Calibre默认输出的语言是中文,在kindle上无法设置bookerly等英文字体。
Calibre 界面上的“抓取新闻”功能没有太多可定制的地方,所以要用变通的方法。这里说两种可行方案,你可以根据自己的情况自行选择:
方案一:将抓取脚本保存为 .recipe 文件,向脚本中添加一行代码
language = 'en',然后将此脚本拖放到 Calibre 书库,最后通过右键菜单转换,将输出格式选择为 AZW3 格式即可。方案二:将抓取脚本保存为 .recipe 文件,然后使用如下命令直接将抓取的新闻转换成 AZW3 格式:
* 关于 ebook-convert 命令的使用可参考《Calibre 常用命令行工具详解之 ebook-convert》这篇文章。
请问怎么将抓取脚本保存为.recipe文件
如果你指的是 Calibre 内置的抓取新闻的 Recipe 脚本,可以通过两种方式获取脚本代码:一种是点击 Calibre 界面上的“抓取新闻”图标右侧的倒三角按钮,在弹出的菜单中点击“添加自定义新闻来源”,在弹出的窗口中点击 【自定义内置订阅清单】按钮,会弹出所有内置的新闻列表,双击选择你想要的新闻,即可显示该新闻的 Recipes 脚本代码;另一种是直接访问 Calibre 项目代码中的 Recipes 目录,所有内置的 Recipes 脚本都存放在这里。
好的,感谢
请问脚本是设置成下面这个样子嘛?为啥设置后抓取到的文章语言还是中文
使用这个脚本抓取的电子书已经将电子书的元数据设置成英文了,在 Kindle 中应该是可以调用英文字体了。
另外我对你留言中的“抓取到的文章语言还是中文”这句话有些疑惑,我不知道我有没有理解你的意思。如果你指的是想要抓取到的内容本身是英文的,那应该清楚,把电子书的元数据设置成英文和抓取到的文章语言是否是英文是两回事,抓取到的文章是什么语言取决于 RSS 供稿本身提供的内容。
我的意思是抓取的内容还是只能设置中文字体,不能设置英文字体。
抓取可以设置存到固定书库吗?老是要移动
固定书库和移动是什么意思?
是这样的,每次打开calibre开始抓取新闻,然后新闻会被存储在当前书库下,但是我一般将抓取的新闻存放在固定书库,这就导致我需要频繁移动新闻到指定书库
可能我对你的使用习惯不太了解,所以不太确定是否理解了你的描述。Calibre 只能设置一个书库,抓取新闻功能会把转换好的文件直接放入书库列表中。你所说的“固定书库”是指独立于 Calibre 书库之外的某种形式的存储方式吗?还是说使用了 Calibre 的“虚拟书库”功能把书库进行了分类,你想把抓取的文件自动归类?
mac环境下抓取新闻需要配置环境变量么
抓取本身不需要配置。如果你要抓去的新闻源是在墙外,则需要全局代理。
Calibre如何把抓取的文章输出为mobi? 亚马逊不支持epub格式转送了?
尊敬的客户,
您从2019年8月18日9:52 发出的如下文档无法发送到您指定的Kindle上:
* Wo De Xin Wen Yuan [Zhou Ri , 18 8Yue 2019] – calibre.epub
Kindle个人文档服务目前只能转换并发送以下类型的文档:
Microsoft Word (.doc, .docx)
RTF文件(.rtf)
HTML(.htm, .html)
TXT文件(.txt)
Zip, x-zip压缩文件
Mobi格式电子书
JPEG (.jpg), GIF (.gif), Bitmap (.bmp) 和 PNG (.png) 格式的图片。
Adobe PDF (.pdf)文档可维持原文件格式,发送至您的Kindle。
Adobe PDF (.pdf)文档可转换为Kindle格式发送,目前处于试用阶段。
如上述格式的文档未成功发送,请确认文档是否受到密码保护或被加密。特别说明,目前最新的Kindle支持读取受密码保护的PDF文档。
亚马逊的个人文档服务从来没有支持过 EPUB 格式。你需要转换时把输出格式选为 MOBI 格式。
怎样删除calibre内置的自定义订阅清单?谢谢。
发现淘宝上有2家卖KindleEar账号的。
微信群反馈问题经重试已解决,不作回复。KindleEar 是开源软件,使用者遵循软件作者要求的 AGPLv3 许可即可。