
GitBook 制作 Kindle 电子书详细教程(可视化版)
* GitBook 已改版,本教程已失效。
GitBook 是一项致力于文档编制、数码写作和出版的新型、简单的解决方案。它不仅提供了简单且强大的电子书创建工具 GitBook,同时还提供了在线电子书制作平台服务 GitBook.com。
GitBook 是一款基于 Node.js 开发的开源的工具,可以直接在本地创建电子书项目。GitBook.com 是一个在线创建、发布和管理电子书的服务平台。两者都是免费的。你可以利用它们使用 MarkDown 编写电子书内容,然后生成 PDF、ePub、mobi 格式的电子书,或生成一个静态站点发布到网络上。
如果你用过 Git 的话应该对 Github 不陌生,GitBook 中有一个“Git”,说明它也可以用 Git 进行版本控制。需要说明的是,虽然 GitBook 和 GitHub 如此相像,但仍然是两个独立的项目,非从属关系。
以上是 GitBook 的简单介绍。即便你不懂什么是 Git 也没关系,只需要明白使用 GitBook 可以制作适用于 Kindle 阅读的 mobi 格式电子书即可。
因为受众不一样,所以 Kindle 伴侣把 GitBook 制作 Kindle 电子书的教程分成“可视化版”和“命令行版”两个版本。前者主要面向一般受众,友好的可视界面、傻瓜式操作,极易上手。后者是给喜欢使用命令行操作的小伙伴准备的,纯文本编辑器即可搞定一切,极客十足。形式不同,结果是一致的。
本文是“可视化版”教程。虽然也分成了“在线制作电子书”和“桌面客户端制作电子书”两种,但不论是界面还是操作其实没有差别,哪个顺手就用哪个吧,或者结合着使用也不错。
目录
一、在线制作电子书
1、注册并创建电子书项目
2、添加、编辑电子书内容
3、电子书简介和导航目录
4、配置、词汇表和 CSS
5、添加自定义电子书封面
6、生成 mobi 格式电子书
二、桌面客户端制作电子书
一、在线制作电子书
在线制作电子书的方式是最简单易行的,所有操作只需要浏览器就可以完成。
1、注册并创建电子书项目
首先,按照下面的步骤,注册一个帐户并创建一个新的电子书项目。
- 点击链接 ( https://www.gitbook.com ),注册一个 GitBook 账号;
- 注册成功后会自动进入控制面板,点击【Create your first book】按钮创建一本新书;
- 输入“Title(标题,即书名)”、“URL(地址名)”、“Description(简介)”;
- 选择“Public”模式(Private 为收费模式),点击【Create Book】完成创建。
2、添加、编辑电子书内容
现在已经成功创建了一个空的电子书项目。接下来就可以往里面填充内容了。点击【Start Writing】按钮即可进入如下图所示的电子书编辑界面。下面的内容会详细介绍界面功能。
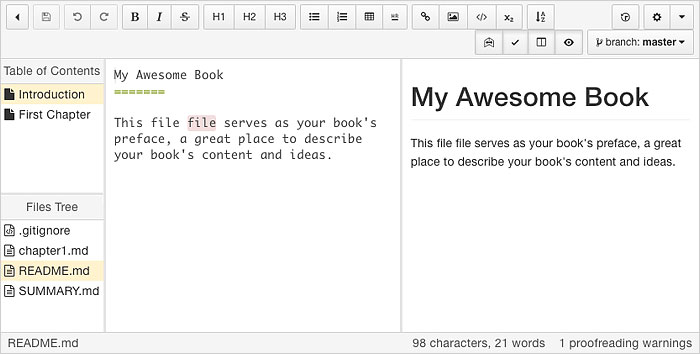
界面最上方是“功能栏”。左侧边栏上为“目录区”,左栏下为“文件树”,中栏为“编辑区”,右栏为“预览区”。最底部为“状态栏”。下面对这几个区域做详细介绍。
① 功能栏:操作、编辑功能按钮
功能栏可以大致分成四个部分,下面从左到右依次说明一下。
![]()
控制按钮:返回控制台、保存、撤销、重做。
![]()
编辑按钮:加粗、斜体、删除线、H1 标题、H2 标题、H3 标题、无序列表、有序列表、表哥、hr 分割线、链接、插入图片、代码块、数学表达式、(书尾)词汇表
![]()
视图按钮:编辑预览区同步滚动、英文校验、关闭/显示左侧边栏、关闭/显示预览区
![]()
设置按钮:选择分支、版本历史、编辑器设置、其它设置项(如: Edit Book Configuration(编辑电子书设置)、Edit Book Cover(添加电子书封面)、Stylesheets(添加样式表)等。
② 目录区:编辑电子书的目录
“目录区”显示的章节结构即电子书开头的“Table of Contents(目录)”显示的内容。
默认会有“Introduction”和“First Chapter”两个章节示例,你可以通过右键菜单“Edit(编辑)”将其重命名,重新编辑它们的内容。也可以干脆通过右键菜单“Delete”把它们删除(“Introduction”无法删除)。
然后通过右键菜单“New Article(新文章)”新建章节,在弹出的对话框中输入章节名称。点击新建的章节名,还会弹出一个对话框,需要输入和此章节名对应的文件名。如果你输入的是中文,如“第一章 XXXXX”,则会自动转换成“di_yi_zhang_XXXXX.md”,你可以按照自己的喜好更改成更统一的名称,如“Chapter001.md”。然后点击【Create File】即可生成和章节相对应的文件,再进行内容的编辑。
③ 文件树:管理电子书的文件
“文件树”中后缀名为 .md 的章节文件是和“目录区”的章节名相对应的。
在这个区域可以通过右键菜单进行相关操作,如通过“New File(新文件)”新建章节文件,“New Folder(新建文件夹)”新建一个文件夹,“Upload(上传)”上传文件,“Upload Folder(上传文件夹)”上传整个文件夹的内容。以及“Rename(重命名)”、“Delete File(删除文件)”常规操作。
注意,新建文件或文件夹支持路径,如新建文件时输入“text/Chapter.md”,会新建一个名为“text”的文件夹,内含一个名为“Chapter.md”的文件,新建文件夹同理。
另外文件树还支持拖放操作,这可以很方便的管理和电子书相关的如图片、CSS 样式表等文件。比如可以新建一个“images”文件夹,把所有图片都规整到该文件夹中。
④ 编辑区:编辑电子书的内容
这里是电子书正文内容编辑区域,支持 MarkDown 代码,如果你不会使用 MarkDown 也没有关系,可以通过功能栏的“编辑按钮”或右键菜单的“编辑项”对选中文本进行格式化。
注意,在插入图片的时候,尽量使用“From disk(来自本地硬盘)”而不要使用“From url(来自网络链接)”,否则在 Kindle 中阅读该电子书时可能会无法正常显示。
还有就是插入代码的时候(如 HTML 代码),需要先点击功能栏中的“Code(代码)”按钮插入或手动输入 ``` Code Here ```,再在把代码贴到“Code Here”处,如下所示。否则会被编辑器解析。
```
<div><a href="#">链接</a></div>
```
⑤ 预览区:预览电子书内容
此为实时预览区,在“编辑区”录入的内容可以实时地在这里看到效果。
⑥ 状态栏:字符数和拼写警告
状态栏左侧显示当前“文件树”中选中的文件。如果选中的事 .md 章节文件,右侧还会显示字符书、英文单词数,以及英文拼写检查的警告数(对中文没作用)。
3、电子书简介和导航目录
电子书的简介和导航目录别对应着“文件树”中 “README.md”和“SUMMARY.md” 这两个文件。
① README.md
“README.md”是电子书的介绍内容。相当于书籍的扉页内容。
② SUMMARY.md
“SUMMARY.md”包含了书目,即章节结构(也就是在使用 Kindle 看电子书的时候调出顶部功能导航,点击【前往】按钮时弹出的目录导航内容),它的基本结构如下所示:
# Summary
* [第一节](section1/README.md)
* [第二节](section2/README.md)这是 GitBook 根据目录的结构自动生成的一段 MrakDown 代码,一般不需要手动编辑。在“目录区”调整章节顺序,“SUMMARY.md”中的代码会随之自动更新。不过,当你需要“子章节”的时候,则需要手动将此文件中的章节名使用“Tab”键缩进一下(最多支持三级标题),如下所示:
# Summary
* [第一节](section1/README.md)
* [样例 1](section1/example1.md)
* [样例 2](section1/example2.md)
* [第二节](section2/README.md)
* [样例 1](section2/example1.md)注意,这种缩进好像在 Kindle 的“前往”中并未生效。
4、配置、词汇表和 CSS
这三项不是必须的。默认情况下“文件树”中没有“book.json(电子书配置文件)”、“GLOSSARY.md(书尾词汇表)”和 “Style(CSS 样式表)”的。
① book.json
点击界面右上角、功能栏最右侧的小倒三角按钮,在弹出的菜单中点击“Edit Book Configuration(编辑电子书设置)”便会在“文件树”中生成一个名为“book.json”的文件。
“book.json”是电子书的配置文件,可以看作是电子书的“原数据”,比如 title、description、isbn、language、direction、styles 等,更多点击这里查看。它的基本结构如下所示:
{
"title": "我的第一本電子書",
"description": "用 GitBook 制作的第一本電子書!",
"isbn": "978-3-16-148410-0",
"language": "zh-tw",
"direction": "ltr"
}② GLOSSARY.md
对于电子书内容中需要解释的词汇可在此文件中定义。词汇表会被放在电子书末尾。其格式如下所示:
# 电子书
电子书是指将文字、图片、声音、影像等讯息内容数字化的出版物和植入或下载数字化文字、图片、声音、影像等讯息内容的集存储和显示终端于一体的手持阅读器。
# Kindle
Amazon Kindle 是由 Amazon 设计和销售的电子书阅读器(以及软件平台)。用户可以通过无线网络使用 Amazon Kindle 购买、下载和阅读电子书、报纸、杂志、博客及其他电子媒体。③ CSS 样式表
点击界面右上角、功能栏最右侧的小倒三角按钮,在弹出的菜单中点击“Stylesheets(样式表)”便会在“文件树”中生成和输出格式相对应的 CSS 样式表文件。
至于给 mobi 文件添加 CSS 样式表显得有些奇怪。因为 GitBook 生成的 MOBI 文件是 mobi7 标准,是不支持样式表的,不知道这里添加样式表有什么意义。
5、添加自定义电子书封面
默认状态下 GitBook 会默认生成一个电子书封面,如果想要自定义封面,只需要点击界面右上角、功能栏最右侧的小倒三角按钮,在弹出的菜单中点击“Edit Book Cover(编辑书籍封面)”选择一张合适的封面图片即可。GitBook 帮助文档建议封面图片的尺寸为 1800*2360 像素并且遵循建议:
- 没有边框
- 清晰可见的书本标题
- 任何重要的文字在小版本中应该可见
6、生成 mobi 格式电子书
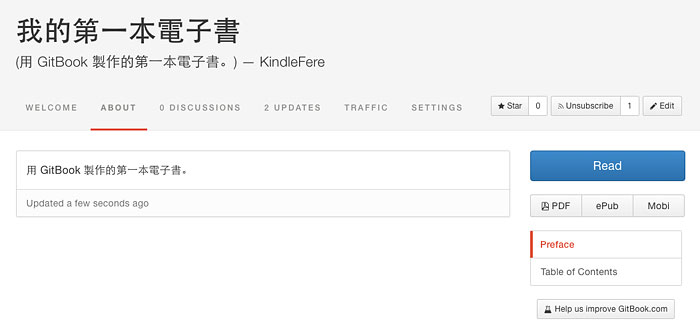
编辑完成电子书内容后。点击界面左上角的“Return to dashboard(返回控制面板)”返回到电子书项目主页。在页面右侧有一个蓝色的【Read】按钮,点击即可在线预览。点击按钮【Read】下面的【Mobi】按钮,即可下载到适合 Kindle 阅读的 mobi 格式电子书文件。
二、桌面客户端制作电子书
除了用 GitBook.com 在线创建、编辑电子书外,还可以使用 GitBook 提供的桌面客户端完成相同的工作。GitBook 目前提供了适用于 Mac、Windows 和 Linux 的桌面客户端,其界面和操作习惯和线上一模一样。客户端最大的好处是可以离线操作,在没有网络的情况下可解燃眉之急。
GitBook 桌面客户端官方下载页面:https://www.gitbook.com/editor
下载、安装并打开 GitBook 桌面客户端,并使用你的 GitBook 帐号登录。在界面上方可以看到“LOCAL LIBRARY”和“GITBOOK.COM”两个选项卡。前者的列表是在本地创建或从 GitBook.com 上克隆下来电子书项目,后者的列表是托管在 GitBook.com 上的电子书项目。
你可以从“GITBOOK.COM”里把托管的电子书项目“Clone(克隆)”到本地进行编辑,完成后点击功能栏右边的“Sync(同步)”按钮同步到 GitBook.com 上。
当然也可以在“LOCAL LIBRARY”创建本地电子书项目,不过需要注意的是,直接在本地创建的电子书不能直接上传到 GitBook.com 上。所以为方便起见,推荐您先在 GitBook.com 上创建电子书项目,然后用客户端把项目克隆到本地,再进行编辑、同步操作。
不过可惜的是客户端不能直接生成 mobi 电子书,还需要登录 GitBook.com 下载。
© 「书伴」原创文章,转载请注明出处及原文链接:https://bookfere.com/post/287.html
“制作Kindle电子书”相关阅读
- 乐书:在线 Kindle 电子书制作和转换工具
- 如何更改阿拉伯语、维吾尔语电子书的文字方向
- 如何为 Kindle 电子书添加嵌入多种自定义字体
- Kindle 漫画制作软件 ChainLP 简明教程
- Calibre 使用教程之抓取 RSS 制成电子书
- GitBook 制作 Kindle 电子书详细教程(命令行版)
- 如何制作完美的 Kindle 期刊杂志格式排版的电子书
- Calibre 使用教程之抓取网站页面制成电子书
- 亚马逊 Kindle Convert:纸质书无损转换电子书
- 如何给自制 Kindle 电子书添加弹出脚注或尾注
- Sigil 进阶教程:从零开始制作 EPub 电子书
- Sigil 基础教程(二):Sigil 的基本操作
- 亚马逊 Kindle 电子书发布指南(二)一般最佳实践
- 遵循亚马逊标准!Kindle 电子书专业制作教程
- 亚马逊推电子书制作工具 Kindle Textbook Creator
您好!新年吉祥!
感谢您的网站内容,想请教一下,如何快速批量导入多层次的html网站制作电子书?
现有这样的网站内容,都是html,http://www.lingshh.com/
但是分了好几个目录层次的
希望全站下载之后,快速批量制作成带有母子目录层次结构的电子书,用什么工具最快呢?
感谢!
想要快速导入最好的方法是用软件自动抓取,具体方法可参考《Calibre 使用教程之抓取网站页面制成电子书》这篇文章。
谢谢!这个网站只有两三个层级,但是我试着这个代码,抓取不成功……
那篇文章只是提供了一个示例,不能直接套用的,因为每个网站的 HTML 代码结构不一样,所以需要根据具体的结构编写脚本,这需要你懂点 Python。
我看了一下你提供的这个网站,内容类型比较杂乱,有 HTML 格式还有 DOC 格式,DOC 格式不能直接抓取,除非你使用代码单独对其进行处理。下面这个代码可以抓取所有的 HTML 页面,但是会忽略 DOC 格式:
当然这个脚本抓取的结果也是比较粗糙的,想要更精细的控制内容,就需要用添加 Python 代码慢慢细化了。
感谢您!
只需要html即可,不需要doc等文件:)
但是尝试运行,仍然失败了
抓取新闻,来源于 真如是
Conversion options changed from defaults:
verbose: 2
Resolved conversion options
calibre version: 3.42.0
{‘asciiize’: False,
‘author_sort’: None,
‘authors’: None,
‘base_font_size’: 0,
‘book_producer’: None,
‘change_justification’: ‘original’,
‘chapter’: None,
‘chapter_mark’: ‘pagebreak’,
‘comments’: None,
‘cover’: None,
‘debug_pipeline’: None,
‘dehyphenate’: True,
‘delete_blank_paragraphs’: True,
‘disable_font_rescaling’: False,
‘dont_download_recipe’: False,
‘dont_split_on_page_breaks’: True,
‘duplicate_links_in_toc’: False,
’embed_all_fonts’: False,
’embed_font_family’: None,
‘enable_heuristics’: False,
‘epub_flatten’: False,
‘epub_inline_toc’: False,
‘epub_toc_at_end’: False,
‘epub_version’: ‘2’,
‘expand_css’: False,
‘extra_css’: None,
‘extract_to’: None,
‘filter_css’: None,
‘fix_indents’: True,
‘flow_size’: 260,
‘font_size_mapping’: None,
‘format_scene_breaks’: True,
‘html_unwrap_factor’: 0.4,
‘input_encoding’: None,
‘input_profile’: ,
‘insert_blank_line’: False,
‘insert_blank_line_size’: 0.5,
‘insert_metadata’: False,
‘isbn’: None,
‘italicize_common_cases’: True,
‘keep_ligatures’: False,
‘language’: None,
‘level1_toc’: None,
‘level2_toc’: None,
‘level3_toc’: None,
‘line_height’: 0,
‘linearize_tables’: False,
‘lrf’: False,
‘margin_bottom’: 5.0,
‘margin_left’: 5.0,
‘margin_right’: 5.0,
‘margin_top’: 5.0,
‘markup_chapter_headings’: True,
‘max_toc_links’: 50,
‘minimum_line_height’: 120.0,
‘no_chapters_in_toc’: False,
‘no_default_epub_cover’: False,
‘no_inline_navbars’: False,
‘no_svg_cover’: False,
‘output_profile’: ,
‘page_breaks_before’: None,
‘prefer_metadata_cover’: False,
‘preserve_cover_aspect_ratio’: False,
‘pretty_print’: True,
‘pubdate’: None,
‘publisher’: None,
‘rating’: None,
‘read_metadata_from_opf’: None,
‘remove_fake_margins’: True,
‘remove_first_image’: False,
‘remove_paragraph_spacing’: False,
‘remove_paragraph_spacing_indent_size’: 1.5,
‘renumber_headings’: True,
‘replace_scene_breaks’: ”,
‘search_replace’: None,
‘series’: None,
‘series_index’: None,
‘smarten_punctuation’: False,
‘sr1_replace’: ”,
‘sr1_search’: ”,
‘sr2_replace’: ”,
‘sr2_search’: ”,
‘sr3_replace’: ”,
‘sr3_search’: ”,
‘start_reading_at’: None,
‘subset_embedded_fonts’: False,
‘tags’: None,
‘test’: False,
‘timestamp’: None,
‘title’: None,
‘title_sort’: None,
‘toc_filter’: None,
‘toc_threshold’: 6,
‘toc_title’: None,
‘transform_css_rules’: None,
‘unsmarten_punctuation’: False,
‘unwrap_lines’: True,
‘use_auto_toc’: False,
‘verbose’: 2}
InputFormatPlugin: Recipe Input running
Downloading recipe urn: custom:1000
Python function terminated unexpectedly
No articles found, aborting (Error Code: 1)
Traceback (most recent call last):
File “site.py”, line 101, in main
File “site.py”, line 78, in run_entry_point
File “site-packages\calibre\utils\ipc\worker.py”, line 200, in main
File “site-packages\calibre\gui2\convert\gui_conversion.py”, line 35, in gui_convert_recipe
File “site-packages\calibre\gui2\convert\gui_conversion.py”, line 27, in gui_convert
File “site-packages\calibre\ebooks\conversion\plumber.py”, line 1107, in run
File “site-packages\calibre\customize\conversion.py”, line 245, in __call__
File “site-packages\calibre\ebooks\conversion\plugins\recipe_input.py”, line 137, in convert
File “site-packages\calibre\web\feeds\news.py”, line 1024, in download
File “site-packages\calibre\web\feeds\news.py”, line 1203, in build_index
ValueError: No articles found, aborting
你输入的命令是什么呢?我测试用的 Calibre 版本是 3.48.0,你可以下载这个版本试试看。
已经升级到4.9.1最新版:但是抓取新闻,还是提示错误:
calibre, version 4.9.1 (win32, embedded-python: True)
转换错误: 失败: 抓取新闻,来源于 真如是
抓取新闻,来源于 真如是
Python function terminated unexpectedly
(Error Code: 1)
Traceback (most recent call last):
File “site.py”, line 114, in main
File “site.py”, line 88, in run_entry_point
File “site-packages\calibre\utils\ipc\worker.py”, line 209, in main
File “site-packages\calibre\gui2\convert\gui_conversion.py”, line 36, in gui_convert_recipe
File “site-packages\calibre\gui2\convert\gui_conversion.py”, line 28, in gui_convert
File “site-packages\calibre\ebooks\conversion\plumber.py”, line 1049, in run
File “site-packages\calibre\ebooks\conversion\plumber.py”, line 993, in setup_options
File “site-packages\calibre\ebooks\conversion\plumber.py”, line 947, in read_user_metadata
File “site-packages\calibre\ebooks\metadata\__init__.py”, line 357, in MetaInformation
File “site-packages\calibre\ebooks\metadata\book\base.py”, line 100, in __init__
File “site-packages\calibre\ebooks\metadata\book\formatter.py”, line 10, in
File “site-packages\calibre\utils\formatter.py”, line 16, in
MemoryError
提示 MemoryError 可能是网站的内容比较多导致内存不足导致的,建议分批抓取。下面是更改后的代码,其中变量 feeds 是手动指定的三个文章列表,你可以按照那个格式自行添加:
成功了!非常棒!感恩您:)
不过,我是手工制作这些文件名的……
如何才能自动让软件识别网页上的 链接名字 + 对应的地址,得到这种格式呢?
(‘蔡日新文集’, ‘http://www.lingshh.com/cairx/mulu.htm’),
就是手动指定的。如果你想一次性把链接提取出来,可以自己写点代码提取,下面是提取好的,你直接添加就行了:
谢谢!
不过可能内容太多了,获取新闻,迟迟无法结束……
以后还会遇到很多这种网页,需要自动识别网页上的 链接名字 + 对应的地址,如何才能实现呢?
(‘蔡日新文集’, ‘http://www.lingshh.com/cairx/mulu.htm’),
可能你没理解我的意思。我给你的列表是方便你手动添加,不是一次性添加进去,否则就和一开始给你的那个抓取页面所有链接的代码作用是一样的了,因为内容过多,最后还是可能会遇到内存错误。给你的建议还是之前说过的,手动设置链接,分批抓取。
对于不同的网页,不同的内容结构,就需要对脚本做相应的调整,没有一种一劳永逸能适配所有的网页内容的脚本。
不知有没有更好的解决方案?谢谢:)
建议先重启以下 Kindle 看能否缓解这个问题。如果重启之后仍然频繁重现,建议不要使用自定义字体,或者参考《Calibre 使用教程之为电子书添加更换字体》这篇文章,将字体内嵌到电子书中。
Kindle 系统是封闭的,除非越狱,否则没有更好的更换字体的方案。
好可惜,这麽好的软件居然失效了。
感謝教學!
補充一下,兩個月前電子書發佈功能已經預設為關閉了,所以要到自己的GitBook首頁,點選書本右邊的三角鍵頭→設定書本,然後把電子書功能打開,這樣才有epub, mobi或PDF可以下載喔!
詳見官方說明
https://www.gitbook.com/blog/features/ebooks-option
用gitbook导出的pdf电子书中文字体一大一小,歪歪斜斜,您知道怎么解决吗?