
ABBYY FineReader:把扫描版 PDF 转换成文本
Kindle 阅读 PDF 文档是一个老大难的问题。文字版的 PDF 可以在推送到云端时,主题填写“convert”,让亚马逊服务器转换成适合 Kindle 阅读的排版格式。但是对于扫描边的 PDF 就没什么完美的解决方案了,一般的方法就是重排 PDF 文档或横屏阅读,除了这两种,其实还有一个方法,那就是使用 OCR(Optical Character Recognition,光学字符识别)软件把扫描版的 PDF 转换成文字版本。https://bookfere.com/post/239.html
这次给小伙伴们推荐的就是这么一款强大的 OCR 软件——ABBYY FineReader。ABBYY 是一家俄罗斯软件公司,在文档识别,数据捕获和语言技术的开发中居世界领先地位。旗下产品 ABBYY FineReader Professional 是一款真正的专业 OCR,不仅支持多国文字,还支持彩色文件识别、自动保留原稿插图和排版格式以及后台批处理识别功能,使用者再也不用在扫描软件、OCR、WORD、EXCEL之间换来换去了,处理文件会变的就像打开已经存档的文件一般便捷。
看起来是个完美的方法,其实不尽然。因为扫描版的 PDF 存在很多问题,比如字迹模糊、版式歪斜等等,也会导致 OCR 识别软件无法正确识别某些字词。另外就是复杂的公式和特殊格式的排版,OCR 软件也不能完全搞定,不过有胜于无,相比手工打字,修正个别识别错误显得更加轻松有效率。
一、软件下载
这是一款收费软件,官方已通知本站下架破解版,请自行搜索资源。
二、软件使用
如果你用过 Word,会发现 ABBYY FineReader 的界面很熟悉,它的使用很简单,只需要打开 PDF 文档即可自动识别(除了 PDF 格式还支持其他各种各样的图片或文档格式)。如下图所示,最左侧是所有页码,右侧有两栏,左栏是原稿,右栏为识别后的文档。你可以在上方的工具栏中选择不同的“文档布局”以更改识别后文档的版式,这些版式对应着不同的用途,排版也不一样,比如 Word 版式会尽可能精准的复刻原稿地版式,而 epub 格式则更接近于没有任何排版的纯文档格式。
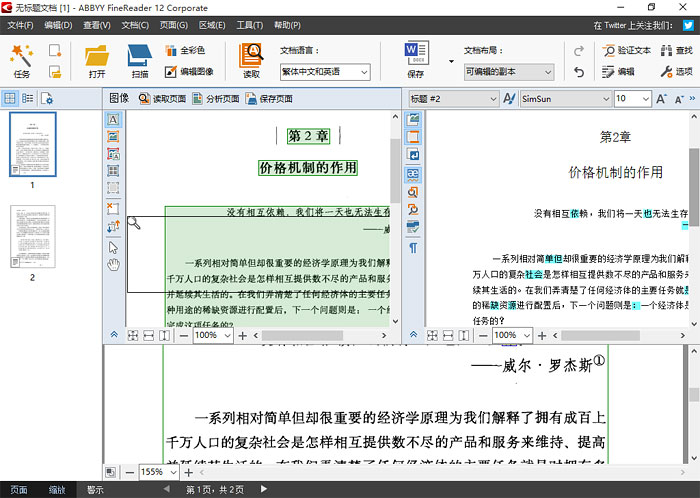
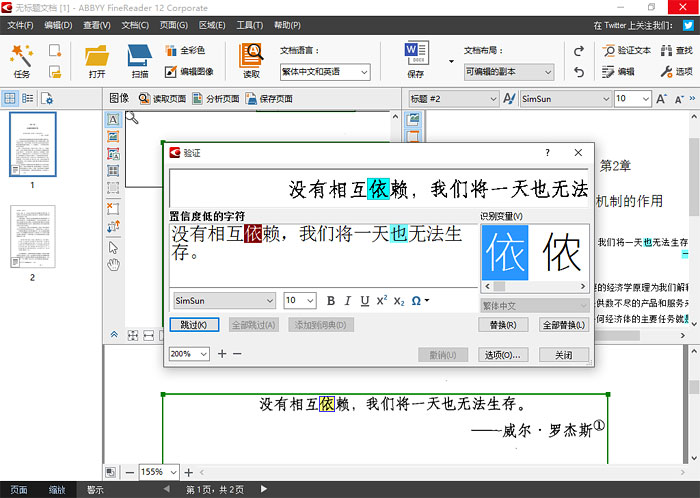
如下图所示,在识别后的文档中,有些青色高亮标注字词,这些是软件“拿不准”的字词,你可以点击界面右上角的“验证文本”,可以根据提示一个一个地修正可能存在识别错误的字词。
处理完毕后,点击上方工具栏中的“保存”,即可把转换好的文档存储成图文版本。
在“保存”的下拉选项中,ABBYY FineReader 还专门为 Kindle 准备了推送项,不过需要注意的是它借助的是你电脑中的邮箱客户端,如果你没有安装邮箱客户端或者没有设置好邮箱客户端,是无法使用的。
三、注意事项
正如本文开始所说的那样,文档扫描的清晰度不一样,识别的精准度也不一样。如下图所示,第一幅图片所示的文档扫描的清晰一些,扫描过后几乎没有错字,而第二幅图片所示的文档扫描的清晰度不高,错字更多一些。所以尽可能使用该软件处理扫描精度更高的文档。


另外,通过不同排版格式的测试,发现该软件对数学公式、编程代码的识别并不怎么精准,所以只推荐识别纯图文形式的、扫描精度足够高的文档。
© 「书伴」原创文章,转载请注明出处及原文链接:https://bookfere.com/post/239.html
延伸阅读
- 如何利用 Sigil 和 EpubCheck 插件检查和修复 EPUB 文件
- [每周一书] 如何避免气候灾难《气候经济与人类未来》
- 克莱顿・克里斯坦森的“创新三部曲”
- [每周一书]《人民的名义》热播剧同名政治小说
- [每周一书]《一炮走红的国家》钱还能去哪儿呢?
- [每周一书]《破碎的生活》时代动荡中普通人的命运
- 如何制作完美的 Kindle 期刊杂志格式排版的电子书
- [每周一书]《原生家庭》如何修补自己的性格缺陷?
- 十六年前首款 Kindle 的杀手级功能改变了我们的阅读方式
- 全新 Kindle Oasis 全球首发资料图抢先预览
- [每周一书] 先看《火星救援》原著的三个理由
- [每周一书]《美国种族简史》从种族看美国
- 亚马逊“只换不修”的 Kindle 售后政策遭质疑
- [每周一书]《在绝望之巅》燃起超脱生死的激情
- macOS 版 Send to Kindle 新增 USB File Manager 应用
翻译出来的文件有一些特殊符号:
例如这些:{{ }}、☑☑☑☑(里面没有打勾),
像出现这些奇怪的符号,是哪里出了问题了吗,需要如何解决
回复错帖子了
您好请问解压密码是多少? 以前下载过
一般本站提供的压缩包密码都是本站域名。
能在发一下网盘连接吗??谢谢!
青芒 您好。抱歉,应版权方要求,已取消网盘下载。
https://www.douban.com/note/366907616/
报告站主,发现一个很有用的东西,方法一,文中的。
这种方法裁剪很快而且对原文保留后,之后再由图片直接重新保存为PDF也非常快,免去了转换MOBI的各种麻烦。
好吧,我错了,还是直接用BIRSS切白边后的效果最好,最能保持原始格式的美感。
WIN下的百度盘已失效
honher 您好。链接已修复,不过百度网盘仍可能会取消链接。
您好!可以分享一下这个文件吗?不方便就算了,打扰了,谢谢。邮箱地址:[email protected]
么老兄,你写的教程实在是太棒了,我可以转载到我的个人公众号(无广告无盈利)上介绍给更多书友吗?
一卓 您好。本站内容均可转载,只需注明出处即可。
win版链接又挂了,请重新放出
一寸 寻 您好。链接已修复。注意,为了防止百度网盘探测文件,压缩包添加了密码。
win版链接挂了,请重新放出
晖过留名 您好。感谢提醒,链接已修复。
如果有onenote pro的话也不错,不过它只能对图片进行转换,可以用软件把PDF批量转化为图片,然后用onenote pro进行文字识别,识别率还不错,大家可以对比一下看哪个识别率更高一些。
好棒 谢谢推荐!
OCR写成了ORC啊……
SevenYuan23 您好。感谢指正,已修改。^_^