
Ebook Translator:用 Calibre 翻译多格式双语对照电子书

- 新增功能:在审阅编辑器中添加行号和同步滚动
- 新增功能:为 Gemini 添加波斯语支持
- 新增功能:改进模型获取提示的清晰度
- 修复:修复导致配置迁移错误的错误
- 修复:修复阻止转换 PNG 和 SRT 文件的错误
- 其他错误修复和功能增强
Ebook Translator 是书伴开发的一款 Calibre 插件,可以将不同格式不同语言的电子书翻译成指定语言(原文译文对照)指定格式的电子书,支持 Google、ChatGPT 和 DeepL 翻译引擎。
在日常的生活、工作或学习中,如果在阅读或翻译外文电子书的过程中需要频繁使用翻译软件,在内容和翻译软件之间来回切换,可能会成为一件颇为痛苦的事。Ebook Translator 插件借力 Calibre 对电子书的强大处理功能和翻译引擎对多种语言的翻译支持,可以轻松将译文添加到原文段落之后,如下图那样形成双语对照,方便辅助对原文的理解或作为译制材料时的参考。

▲ Ebook Translator 插件翻译的电子书效果
借助 Calibre 对多种电子书格式的灵活支持,进行翻译时,你可以自由地选择输入输出格式,比如把 TXT 翻译成为 TXT 或 EPUB,把 PDF 翻译成 PDF 或 DOCX。
Ebook Translator 插件源代码使用 GPL v3 许可证。插件项目托管在 GitHub 上。
一、功能简介
★ Ebook Translator 插件主要包含以下功能:
- 支持“批量模式”和“高级模式”两种翻译模式,应用于不同使用场景
- 支持所选翻译引擎所支持的语言(如 Google 翻译支持 134 种)
- 支持多种翻译引擎,包括 Google 翻译、ChatGPT 以及 DeepL
- 支持自定义翻译引擎(支持解析 JSON 和 XML 格式响应)
- 支持所有 Calibre 所支持的电子书格式(输入格式 48 种,输出格式 20 种)
- 支持批量翻译电子书,每本书的翻译过程同时进行互不影响
- 支持缓存翻译内容,在请求失败或网络中断后无需重新翻译
- 提供大量自定义设置,如将翻译的电子书存到 Calibre 书库或指定位置
★ Ebook Translator 插件支持翻译的语言:
- Google 翻译支持的语言列表
- DeepL 翻译支持的语言列表
- ChatGPT 具体支持语言不详
- 有道翻译支持的语言列表
- 百度翻译支持的语言列表
★ Ebook Translator 插件支持的输入格式:
EPUB, AZW3, AZW4, MOBI, PDF, DOCX, TXT, MARKDOWN, RTF, RECIPE, HTML, HTM, XHTML, XHTM, TXTZ, CB7, ODT, RAR, FBZ, CBC, SHTM, TEXT, SHTML, POBI, UPDB, OPF, TCR, PML, PDB, CHM, SNB, LRF, LIT, RB, DOWNLOADED_RECIPE, CBR, DJV, DJVU, MD, AZW, TEXTILE, DOCM, HTMLZ, PMLZ, CBZ, ZIP, PRC, FB2,SRT,PGN
★ Ebook Translator 插件支持的输出格式:
EPUB, AZW3, MOBI, KFX, PDF, DOCX, TXT, RTF, OEB, TCR, PDB, SNB, LRF, TXTZ, LIT, RB, HTMLZ, PMLZ, ZIP, FB2,SRT,PGN
二、安装插件
首先确保你的操作系统已经安装了 Calibre,然后通过一下任意方式安装本插件:
【方法一】通过 Calibre 安装
- 打开 Calibre 并依次点击其菜单【 首选项… → 插件 → 获取新的插件 】;
- 在插件列表中选中 Ebook Translator 然后点击 【 安装 】 按钮(请留意,首次安装此插件时,要选择把图标显示在主工具栏上);
- 最后关闭并重新打开 Calibre 即可正常使用。
【方法二】通过插件文件安装
NAME: Ebook-Translator-Calibre-Plugin_v2.2.0.zip
MD5: 4eda05385bf2f49d1b8a066b9795e3ab
SHA1: e9bcfc0d02c51dc7dd7d9de9a1f4b0c12e3f6ba0
- 首先在通过以上链接下载插件文件;
- 然后打开 Calibre 并依次点击其菜单【首选项 → 插件 → 从文件加载插件】;
- 在弹出的对话框中选择下载的扩展名为 .zip 的插件文件完成安装(请留意,首次安装此插件时,要选择把图标显示在主工具栏上);
- 最后关闭并重新打开 Calibre 即可正常使用。
如果想安装最新版本,可以访问 https://translator.bookfere.com 点击按钮【Rolling Release】下载。注意,最新版本在每次提交代码时自动生成,未经过严格测试,可能会存在错误。
如果安装插件后,插件图标未出现在 Calibre 的主工具栏上,可以依次点击 Calibre 的菜单【首选项 → 工具与菜单】,在弹出的对话框中点击下拉菜单并选择“主工具栏”,然后在左栏找到并选中插件图标,点击中间的右箭头按钮【>】将其添加到右栏,最后点击【应用】按钮即可。
三、使用方法
Ebook Translator 提供了两种翻译模式,在开启缓存状态下两者共享同一缓存数据。
1、高级模式
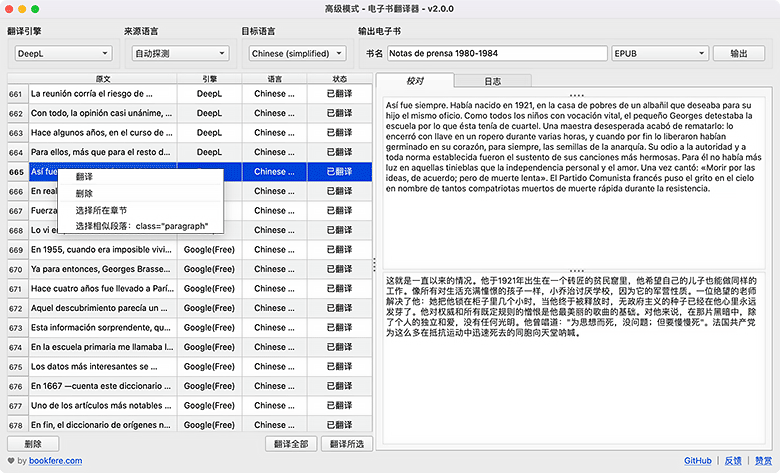
- 在 Calibre 书库中选中要推送的电子书,点击 Calibre 主工具栏上的【翻译书籍】图标按钮,或点击图标下拉菜单选择【高级模式】;
- 在弹出的提示框点击选择“高级模式”(首次打开);
- 选择“输入格式”和“输出格式”,点击【开始】进入“高级模式”翻译主界面;
- 点击【删除】按钮删除需要忽略翻译的选中段落(可选);
- 通过以下两种方式进行翻译:
- 点击【翻译所选】按钮翻译选中的段落
- 点击【翻译全部】按钮翻译全部电子书内容
- 翻译完成后,在右方“校对”区域,通过编辑下方文本并点击【保存】,可以更改翻译结果;
- 点击【输出】按钮,存储翻译完成后的电子书。输出任务将被推送添加到 Calibre 的任务队列。
2、批量模式
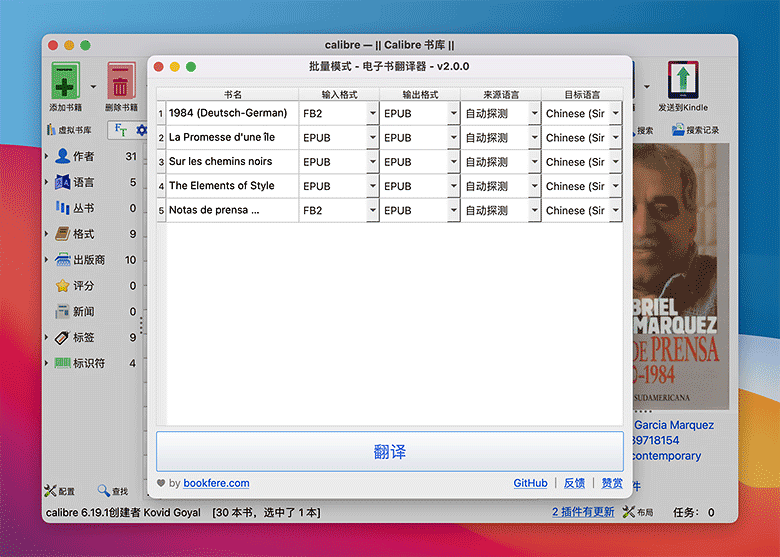
- 在 Calibre 书库中选中要推送的电子书,点击 Calibre 主工具栏上的【翻译书籍】图标按钮,或点击图标下拉菜单选择【批量模式】;
- 在弹出的提示框点击选择“批量模式”(首次打开);
- 进入插件主界面,在这里你可以修改“书名”(作为保存文件时使用的文件名),分别为每一本书选择“输入格式”、“输出格式”、“来源语言”(一般情况下“自动探测”即可满足需求)、“目标语言”(默认使用 Calibre 界面当前所用的语言);
- 点击下方的【翻译】按钮即可开始翻译。
插件会将每本电子书的翻译任务推送添加到 Calibre 的任务队列,你可以通过点击 Calibre 右下角的【任务】查看推送详情,双击任务条目可以进入日志实时查看正在翻译的内容。
三、插件设置
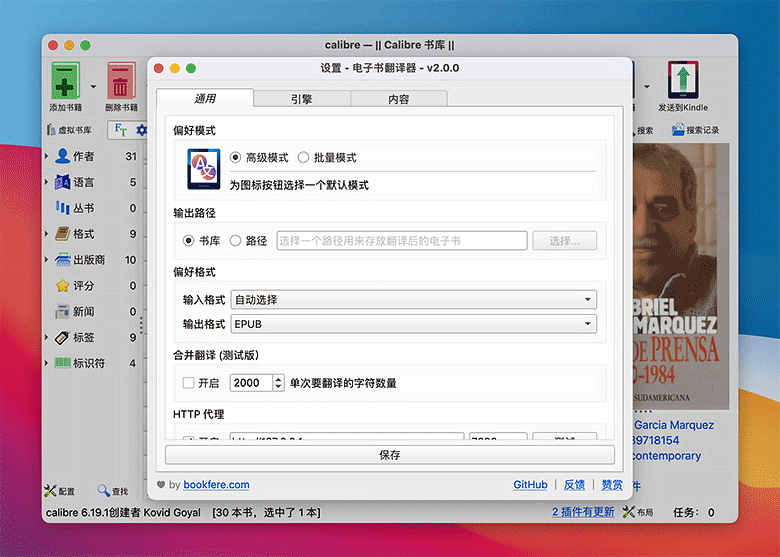
▲ Ebook Translator 通用设置
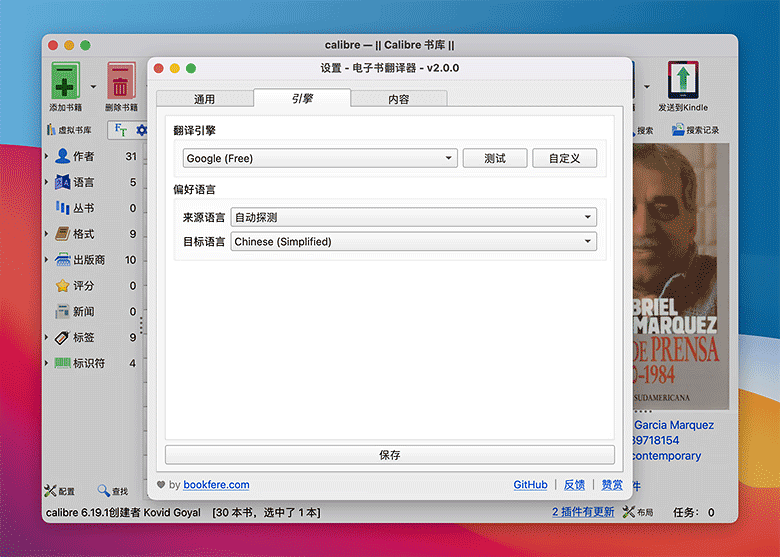
▲ Ebook Translator 引擎设置
▲ Ebook Translator 内容设置
有关设置内容的详细说明请查阅 Ebook Translator 项目的 Wiki 页面。
五、注意事项
开发 Ebook Translator 插件测试用的 Calibre 版本是 3.48 和最新版版本,因此理论上插件在 3.x 到 6.x 版本的 Calibre 中都能正常使用,但是如果版本低于 3.x,可能无法正常使用。
尽管 Ebook Translator 插件在发布会尽可能测试,但仍无法保证在任何情况下不会出现问题。
如果你在使用插件的过程中遇到了问题或有好的建议,欢迎报告错误或提交功能请求。
六、常见问题
1、翻译文件丢失
有些用户反馈翻译完成后无法打开文件,此问题通常发生在 Windows 系统上。在 Windows 系统中,有一个功能叫做 “存储感知”,它会自动清理长时间运行程序的临时文件。
为避免此问题,请通过插件的缓存管理器为缓存另外指定文件夹(请勿选择任何临时目录)。
2、翻译速度太慢
普通翻译服务(如 Google Translate)翻译 1000 个段落通常仅需不到 1 分钟的时间。如果你使用的是 ChatGPT 之类的生成式 AI,耗时则有较大的差异,建议根据服务的速率限制在设置中修改并发请求和请求间隔以加快翻译速度。另外,也可开启合并段落功能大幅提升翻译速度。
3、合并翻译效果
在使用 ChatGPT 时合并翻译功能表现较差,这是因为插件会在合并后的文本中添加标记,由于无法保证 ChatGPT 翻译这些文本后仍会保留这些标记,因此无法保证最终的翻译效果。因此,如果要使用的 ChatGPT 翻译电子书,不建议开启合并翻译功能。
© 「书伴」原创文章,转载请注明出处及原文链接:https://bookfere.com/post/1057.html
延伸阅读
- 亚马逊发布 2022 新款入门版 Kindle:换用 USB-C、提升分辨率
- [每周一书]《字体故事》西文字体的美丽传奇
- [网友投稿] 如何为 Kindle 全平台更换自定义字体
- [Kindle漫画] 用 Kindle 和用智能手机看书的区别
- [2017.04.13] Kindle 阅读器固件升级至 5.8.9
- [每周一书]《性与性格》人人都是雌雄同体
- EpubPress:把打开的多个网页转成一本电子书
- [每周一书] 一个评估、改善和保持《自尊》的计划
- [2020.10.15] Kindle 阅读器固件升级至 5.13.3
- [每周一书]《沟通的艺术》全方位掌握沟通技能
- 漫威漫画将陆续上架亚马逊 Kindle 商城
- 一个翻译时代的逝去:被轻视的文学阅读
- [网友投稿] 多看未root下增加罕见生僻字及替换系统字体
- Kindle 越狱插件资源下载及详细安装步骤
- Sherry推荐图书(十一)——有关心理疾病
您好,我的文件是扫描版的pdf文件,需要转换成什么样的文件才能使用ebook翻译呢?
很遗憾,限于 Calibre 无法很好地处理这种文件,插件也无能为力 :(
mineru 先扫一遍,下载为md格式,导入calibre ,转换为epub格式,ebooktranslator翻译,calibre 正则修,改目录。打完收工!
您好为什么点击翻译显示没有需要翻译的内容?
翻译的是什么格式的文件呢?一般扫描版的 PDF 会出现这种情况,因为它不含文本。
为什么mobi格式的也无法识别到翻译内容呢
OCR之后仍然无法提取
翻译过程中,原文的段落之间会多出“{{id_00000}} {{id_00001}} “这样的字符串,这样翻译出来的文本里面也有,字符串随着段落数量增多序号也会变,请问该如何去除这种字符串?
这些标记是用来保留图片或者指定内容的,如果在翻译过程中出现是正常的,如果翻译完成后还有就是错误了,需要修复。
你好,昨天和今天使用翻译插件的时候,无法翻译,报错如下:
错误信息:Traceback (most recent call last):
File “calibre_plugins.ebook_translator.lib.translation”, line 136, in _translate_text
File “calibre_plugins.ebook_translator.engines.google”, line 53, in translate
File “calibre_plugins.ebook_translator.engines.base”, line 210, in get_result
Exception: 无法解析返回的响应。原始数据: 请问如何解决啊?谢谢。
状态:失败 1 次 / 等待 5 秒
┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈
错误信息:Traceback (most recent call last):
File “calibre_plugins.ebook_translator.lib.translation”, line 136, in _translate_text
File “calibre_plugins.ebook_translator.engines.google”, line 53, in translate
File “calibre_plugins.ebook_translator.engines.base”, line 210, in get_result
Exception: 无法解析返回的响应。原始数据:
Traceback (most recent call last):
File “calibre_plugins.ebook_translator.engines.base”, line 197, in get_result
File “mechanize\_mechanize.py”, line 257, in open
File “mechanize\_mechanize.py”, line 287, in _mech_open
File “mechanize\_opener.py”, line 193, in open
File “mechanize\_urllib2_fork.py”, line 425, in _open
File “mechanize\_urllib2_fork.py”, line 414, in _call_chain
File “mechanize\_urllib2_fork.py”, line 1283, in https_open
File “mechanize\_urllib2_fork.py”, line 1240, in do_open
urllib.error.URLError:
经常出现这个情况。这个是怎么回事?怎么解决?
Exception: 无法解析返回的响应。原始数据:
Traceback (most recent call last):
File “calibre_plugins.ebook_translator.engines.base”, line 197, in get_result
File “mechanize\_mechanize.py”, line 257, in open
File “mechanize\_mechanize.py”, line 287, in _mech_open
File “mechanize\_opener.py”, line 193, in open
File “mechanize\_urllib2_fork.py”, line 425, in _open
File “mechanize\_urllib2_fork.py”, line 414, in _call_chain
File “mechanize\_urllib2_fork.py”, line 1283, in https_open
File “mechanize\_urllib2_fork.py”, line 1240, in do_open
urllib.error.URLError:
这个是怎么回事?怎么解决?
请问可否更新一个使用deepseek apikey的选项呢?
已经解决谢谢
昨天反馈过翻译过的pdf无法转存为pdf或则epub的格式问题,经测试,属于输出过大导致异常,因epub的报错信息提及输出过大问题。
另外,测试mobi和awz3格式输出正常,不过我手头软件貌似打开也存在异常,不知道是慢还是挂掉了,暂未达至渲染输出。
想请教有无简单的处置方式,如自动分块输出,类似自动输出上下册,或者1,2,3集多个文件。
期待,感谢!!
你好,有幸搜索到你的转换插件,并用它翻译英文文档。
实际使用中,碰到翻译后无法【成功】转换为pdf的问题。
原始文档链接为:
https://www.postgresql.org/files/documentation/pdf/16/postgresql-16-A4.pdf
翻译成功,但是翻译后保存失败,试了两次结果都一样,希望能结果。【是不是原始pdf页数太多了?有3000页】
一次报错:
[15160:14988:0101/194937.552:ERROR:gpu_channel_manager.cc(952)] Failed to create GLES3 context, fallback to GLES2.
[15160:14988:0101/194937.552:ERROR:gpu_channel_manager.cc(963)] ContextResult::kFatalFailure: Failed to create shared context for virtualization.
: Loading not complete after 66 seconds, aborting.
Load of clbr://internal.invalid/book/index.html failed
另一次报错:
[14984:10288:0101/171908.827:ERROR:gpu_channel_manager.cc(952)] Failed to create GLES3 context, fallback to GLES2.
[14984:10288:0101/171908.827:ERROR:gpu_channel_manager.cc(963)] ContextResult::kFatalFailure: Failed to create shared context for virtualization.
能增加一個功能,導向自己主機架好的ai之類的,打個比方,像自己網路裡架好了Sakura主機後,然後把翻譯引擎導向自己架好的主機。
只要 AI 提供了 WEB API 就可以利用自定义引擎功能自己添加翻译引擎。
感谢。虽然我没有openai的api,但是通过github上引擎源码里的修改实现了deepseek模型的使用,当然大模型是真的慢。再次感谢!
可以提供一些思路吗,我也想尝试使用deepseek:)
2.3.5使用ChatGPT(OpenAl)翻译引擎,修改api密钥,端点和自定义模型就可以了
感觉翻译速度比较慢有什么提速的方法么?
您好!能不能添加藏文的额语言选项,这个真的很有必要。
请问我把PDF格式的电子书翻译,为什么只给我翻译最后的几句与图书正文无关的话,正文完全没有翻译是什么原因呢
您好,我分别有英语和法语的epub文件,请问有可能将它们制作成双语对照书籍吗?我在阅读普鲁斯特的小说,难度高,机器翻译常常出错。
谢谢。
gpt提示这个
如果输入pdf文件, 译文总是一行一行地分开翻译,无法整段流畅翻译,请问有什么解决方法吗?