
把 TXT 文档转换成带目录的 MOBI 格式电子书
如果你喜欢看小说,对 TXT 文档应该不陌生,但是如果直接将下载到的 TXT 文档转换成 MOBI 格式放到 Kindle 中阅读,就会出现一个问题——缺少目录,你不得不线性阅读不敢跳页,很不方便,那有没有一种有效的方法可以把 TXT 转换成带目录的电子书呢?
答案是肯定的。不过要转换的 TXT 文档内容的章节标题要有一定的规律,就像下面这样,一些能把 TXT 自动转换成带目录电子书的软件或应用也是利用这种规律结合很多正则算法实现的。
第123章 第456节
第123章 章标题 第456节 节标题
第123章
第123节
……
如果需要转换的 TXT 文档内容满足这一点,就可以继续下面的操作了。
一、一点点准备工作
1、支持正则替换的编辑器。本文使用 Sublime Text 2:http://www.sublimetext.com/2
2、电子书转换软件。本文使用 Calibre:https://bookfere.com/tools#calibre
二、检查、修改 TXT 文档
因为在网上下载的 TXT 文档内容格式良莠不齐,需要先简单的检查一下其章节标题是否有规律,有什么样的规律,在这些规律中又有哪些不规则的情况。下图是我随便从网上下载的一本 TXT 格式小说打开的样子,其内容格式不那么规整,刚好适合做个相对复杂的例子。
注意,如果打开 TXT 出现乱码,说明是文本的编码问题。有一个小技巧可以解决这个问题,您可以先使用浏览器打开 TXT 文档,然后全选拷贝,再粘贴到 Sublime Text 等编辑器中。
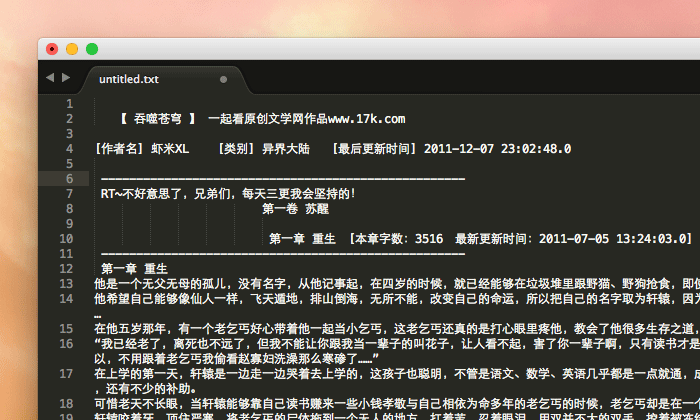
首先,我发现它有如下所示的两种不同形式的章节标题:
第一章 重生
第一章 重生
第二章 谋杀亲夫?
第二章 谋杀亲夫?
……
这里我选择了第二种比较简洁的章节标题作为目录。还需要注意选择的这个章节标题还存在一个不规则的情况,那就是它们有的前面没空格,有的却存在一个空格:
第一章
第二章
第三章
第四章
第五章
……
到此为止我们已经掌握了这个文档里面章节标题规律以及规律中存在的不规则的情况了。接下来,需要给这些章节标题添加一些标记,变成如下这样:
###第一章 XXXXXX
###第二章 XXXXXX
###第三章 XXXXXX
###第四章 XXXXXX
###第五章 XXXXXX
……
在每个章节前边添加的 ### 是 MarkDown 语法,转换成 HTML 就相当于 <h3>,以此类推如果添加 # 就相当于 <h1>,#### 就相当于 <h4>,###### 就相当于 <h6>。
当然,文档中的章节太多,我们不可能一个个手工添加,这就需要用到 Sublime Text 2 的正则表达式替换功能了,可以批量将每个章节标题前面都加上 ### 标记。
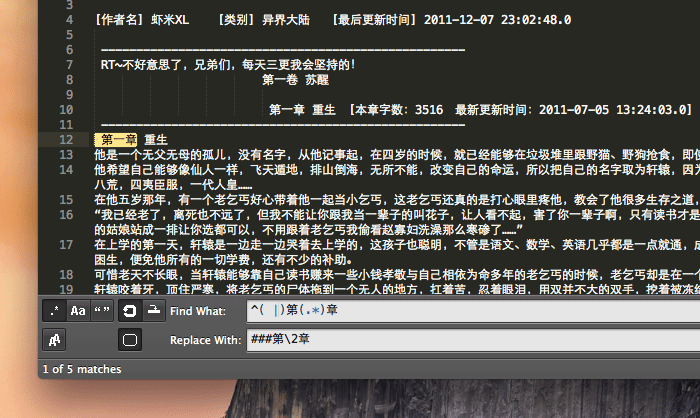
点击菜单“Find → Replace”调出替换功能面板,然后确认选中了面板左侧的正则功能图标【.*】,然后按照下图所示输入,然后点击右侧的【Replace All】按钮,即可完成添加。
如果对正则表达式不是很了解的小伙伴是不是有点儿摸不清头脑?没关系,其实很简单,这里我详细解释一下这一串代码和前面我们已经总结到的章节标题规律之间的关系。
首先在“Find What”中输入的是:
^(\s+|)第(.*)章
第一个字符是 ^ 代表一行的开头。紧挨着的 (\s+|) 里面的 | 代表“或”,因为之前我们发现文档内有的标题前面有空格有的标题前面没空格,它可以把有空格和没空格的都选中。接下来的“第”和“章”是相同的内容,它们之间的 (.*) 代表它们之间的所有内容。这样就选中了所有每一行我们期望修改的章节标题。
接下来“Replace With”中输入的是:
###第\2章
首先 ### 是要添加到标题最前面的字符,接下来的“第”和“章”保持不变,他们中间的 \2 表示前面所选的第二个括号里的内容保持不变。关于更多正则表达式的入门使用方法,可以进入这篇文章,点开“【相关知识】《Sigil正则表达式的入门》”阅读。
下面也提供一些较常用的章节格式的查找替换正则表达式代码:
【标题】第XX章 或 第XX节(不管后面有没有章节名)
【查找内容】第(.*)章 或 第(.*)节
【替换内容】###第\1章 或 ###第\1节
【标题】第XX章第XX节(连在一起的,不管中间或后面有没有章节名)
【查找内容】 第(.*)章第(.*)节
【替换内容】 ###第\1章第\2节
【标题】第XX章AAA第XX节 (中间AAA是空格或章名,不管后面有没有节名)
【查找内容】第(.*)章(.*)第(.*)节
【替换内容】###第\1章\2第\3节
如果您遇到的无法正确查找的章节格式,可以在本文留言求助。
三、转换修改后的 TXT 文档
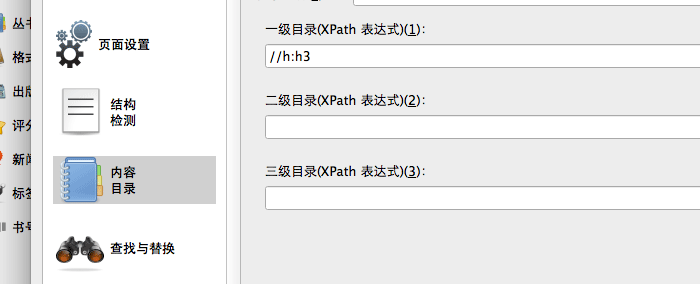
章节标题的标记添加完毕后就可以把修改后的 TXT 文档转换成 MOBI 格式了。打开 Calibre 软件,用鼠标把文档拖进去,然后右键点击它,在弹出的菜单中依次选择“转换书籍 → 逐个转换”,在弹出的窗口中,把右上角的“输出格式”选成“MOBI”,然后点击左栏的“内容目录”标签,找到“一级目录”这一项,填入 //h:h3(也可以点击后面的魔术棒小图标,在弹出的窗口中选择 h3)。
然后切换到“TXT 输入”,在“结构”这一栏找到“格式化样式”并将其设为“markdown”。

提示:“格式化样式”这一项设置的默认值为“auto”,这意味着 Calibre 会自动检测并解析 TXT 文档结构,但是在某些较极端的情况下存在一个问题。以 Markdown 为例,Calibre 仅会在 Markdown 标记大于等于 5 的情况下才会用 Markdown 语法来解析文档,如果 TXT 文档中添加 Markdown 标记的章节标题个数恰好小于 5,就会导致 Calibre 无法正常解析章节标题并生成目录。由于我们明确使用了 Markdown 语法,所以最好的做法是让 Calibre 直接使用此语法解析 TXT 文档。
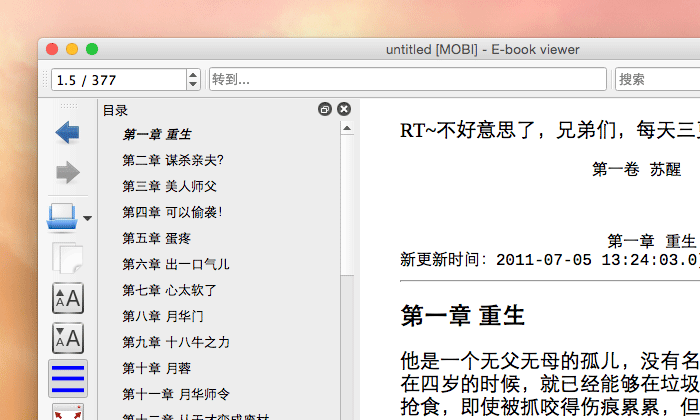
最后点击“确定”按钮,直到转换完成,就可以得到一个从 TXT 转换而来的带有目录的 MOBI 格式电子书了(如下图所示)。如此,仅需学习一遍,今后就可以很快速的处理 TXT 文档了,一劳永逸。
————————
小提示:如果在使用本方法时可能会遇到下面所示的错误。虽然 Calibre 提示 This txt file has malformed markup(文本文件中标记格式错误),却可能是 Calibre 自身的原因。解决方法就是换一种方法,强烈建议使用另一款专门为 TXT 小说转带目录的 MOBI 格式的软件 easyPub,更强大易用。
ValueError: This txt file has malformed markup, it cannot be converted by calibre. See http://daringfireball.net/projects/markdown/syntax© 「书伴」原创文章,转载请注明出处及原文链接:https://bookfere.com/post/82.html
“转换电子书格式”相关阅读
- 如何把 Kindle 电子书转换成增强型排版的 KFX 格式
- 如何把 KFX 格式转换成 MOBI 等其它电子书格式
- Kindle 漫画制作软件 ChainLP 简明教程
- 亚马逊 Kindle Convert:纸质书无损转换电子书
- 在 Kindle 中阅读 EPUB 格式电子书的两种有效方法
- KindleGen:亚马逊官方 Kindle 电子书格式转换工具
- Calibre 使用教程之优化电子书的排版
- Calibre 常用命令行工具详解之 ebook-convert
- Kindle Comic Creator:亚马逊官方漫画转换工具
- 如何直接推送 EPUB 格式电子书到 Kindle 邮箱
- EasyPub:把 TXT 文档转成带目录的 MOBI 格式
- Calibre使用教程之为电子书添加或修改封面
- Calibre 使用教程之转换电子书格式
- EpubPress:把打开的多个网页转成一本电子书
- 如何将 AZW3 格式无损转换为 MOBI 格式并保持原有排版
您好!请教一下,如果是带图文的长篇word文档(是文章合集,一个标题一篇文章),如何方便地制作带标题目录的电子书呢?
比如有没有软件可以将其全部导入,然后把一个个标题加以处理为目录标题?
谢谢!
建议你先直接将 WORD 文档转换成 EPUB 格式,然后用 Calibre 自带的编辑器(或者电子书编辑器 Sigil)来编辑它,把里面的标题应用同样的 HTML 标签(比如统一成
<h1>),编辑好之后,就可以将编辑好的 EPUB 转换成你所需要的其它格式了(比如 MOBI)。转换时在转换设置中切换到“内容目录”填写目录 XPath 表达式填写(比如之前统一成了<h1>,只有一级目录,那就直接在“一级目录”中填写//h:h1即可)。这样比直接处理 WORD 文档要方便一些。使用Calibre从txt转成mobi的时候会丢失内容,比如我转一部网文小说,原来有15个大章节,每个大章节包含50多个小章节。标题都用sublime设置好以后,导入Calibre中转换成mobi,最后出来的成品只有10个大章节的内容,不仅目录只有10个大章节,后面几章节不仅目录没有而且文字也都没了,请问是怎么回事
这个需要测试,可以把你更改好的 TXT 文件发送到书伴的邮箱(页面底部“联系”处获取)。
在txt文件中加了#後沒有生成目錄,例如以下Save成TXT再照上面步驟也不能
是更新後的問題嗎?
建议仔细检查两个关键点,一是为 TXT 添加是英文半角符号的
#,二是用 Calibre 转换时填写正确的表达式,比如添加了两个##表达式就是//h:h2,三个###表达式就是//h:h3,以此类推。检查TXT时,如果编码格式不对,无法打开,建议采用以下办法:用记事本打开,另存为,弹出的保存页面,修改编码格式为UTF-8,保存。再用Sublime Text 2 打开即可。
我找的书 它是第一卷,然后一到二十章;再接着第二卷又是从一开始 这个怎么弄?
有卷章的可以处理成二级目录。预处理时先处理卷,再处理章。比如章用两个井号
##,卷就用三个###,用 Calibre 转换时一级目录表达式为//h:h2二级目录表达式为//h:h3。你好,我标题第x章前都有一个2字符缩进,用教程所示的正则显示Unable to find^(\s+|)第(.*)章,这种要怎么办呢,如果有二级标题,是用“#”和“##”吗
如果缩进是空格应该是能匹配的,你确认编辑器开启正则模式了吗?如果确认开启了,可以试试用这个更宽松的正则
^.*第(.*)章$。关于标题,多一级就多加一个#。我用Calibre这个软件把word文档转换成awz3,发送到手机阅读,“对齐方式:自动”,是虚的,无法选择“连续滚动”方式阅读,不知道是什么原因。
后来用EasyPub这个软件把txt转成mobi格式,在安卓手机kindle软件中还是无法滚屏阅读,只能一页一页的翻看,不知道怎样转换word文档才能在安卓手机kindle软件中可以上下滚动阅读,谢谢!
这个功能是亚马逊为 Kindle 商店里的电子书准备的吧,个人文档应该是享受不到了。
请问如果标题是纯数字的,像这样
001 这是第一章
002 这是第二章
应该怎样替换呢?谢谢
查找内容
^(\d+)替换内容###\1。请问如何用Calibre制作具有章节跳转功能的目录呢?需要什么特定格式吗?
Kindle 电子书有两种目录,一种是 NCX 目录,也就是可使用“前往”功能跳转的目录,另一种是 HTML 格式的 TOC 目录,一般会以普通页面的形式放在电子书的开头(或末尾)。Calibre 默认会生成这两种目录,只是 TOC 目录默认会被放末尾,如果你想放到开头,需要在转换设置的“MOBI输出”中勾选“在生成的书籍开始处插入目录,而不是放在末尾”。
谢谢!
你好 我找了一本mobi电子书 在电脑上看正常 在kindle上换行不正确 比如这样
这张表格中,伯克希尔1978年及之前年度的业绩被修订,以符合修改后
的会计规则。在本表所有的其他方面,我们的业绩结果都是使用最初报告的数字进行计算。
不知从哪儿下手
Kindle 对表格的显示比较弱,对于复杂表格的显示可能不怎么好。对于你所说的这个问题,在这里看不到这个表格的效果,仅凭文字描述没有办法准确理解你的意思。建议把文件放到网盘,然后贴一个链接,以便测试。
您好,请问如何实现每一章节都是新一页?我按照您评论的转成azw3的格式,新章仍是接在上一章结尾位置。
您好,请问一下还有没有什么方法能实现每一章节都是另起一页,我制作的书每一章节之间都只隔了一行的距离,之前试过了在转换书籍的时候改成both模式,但是好像依然不行诶
你可以将其装换成 AZW3 格式,MOBI7 不会分割页面,但是 KF8 标注你的 AZW3 会按照章节自动分割页面。
怎么在Sublime Text 2中将TXT保存成MOBI文件?还有就是Find What 中到底该输入( |)还是(\s+|)…..第一次用,请求指教。
Sublime Text 只能编辑 TXT 文档,转换成 MOBI 格式需要使用 Calibre 这款软件。在正则中
( |)和(\s|)的作用看起来是一样的,它们的区别是,空格仅匹配空格,而\s可匹配包含空格、空白制表符、回车等在内的任何空白。在匹配空格的时候,不带 + 号的\s仅匹配一个空格,带 + 号的\s+会匹配连着的所有空格。虽然已经加好了###,可是在calibre里面转换,就是没有目录生成是怎么回事啊
建议仔细按照本文提供的步骤检查你的操作,确保没有漏掉必要步骤。
请教是否有方式让每一章节title一定为一页的首行?
谢谢~~
请教去除两个特定字符串之间的内容:
“------题外话------
啊哦~播报到处结束,明儿咱两继续……
……
017米 吃、喝、玩、乐”
想去除017米(这是章节号)前的题外话。
假设“题外话”下面的文字有两行,可以查找:
^.*题外话.*\n.*\n.*\n(\d+)米,替换成:\n$1米。注意这里的\n.*表示的是选中换行内容,有几行就加几个。请问一下,像那种每一章节的前面没有第几章第几章的标题是
南方北方:balabalabala
……..
南方北方:balabalabala
………
这种情况下怎么替换成
第一章 南方北方:balabala
第二章 南方北方:balabala
谢谢~
正则表达式只能查找替换已有的字符,不能无中生有,所以不能实现你想要的这种效果。