
如何用 KindleEar 推送无 RSS 的网站内容(下篇)
在本文的“中篇”,我们已经编写好了一个可以正常工作的 KindleEar 订阅脚本,但是用它生成的电子书存在着很多问题,比如没有设定抓取文章的时间范围,也没有处理文章列表和文章内容的翻页,文章标题还带有冗余信息。本文将继续完善订阅脚本,对这些细节进行处理,让生成的电子书更加完美。
目录
[ 上篇 ]
一、KindleEar 的订阅方式
二、KindleEar 的订阅脚本
三、KindleEar 的调试环境
1、安装 App Engine SDK
2、获取 KindleEar 源代码
3、在本地运行 KindleEar
[ 中篇 ]
一、新创建一个订阅脚本
二、订阅脚本的工作原理
三、从网站抽取文章 URL
四、分析 HTML 标签结构
1、分析文章列表的 HTML 标签结构
2、分析文章内容的 HTML 标签结构
五、测试订阅脚本的推送
[ 下篇 ]
一、文章列表的翻页和限定条目
二、文章内容的翻页和细节修改
三、上传到 Google App Engine
以下内容分为三部分:首先是文章列表的翻页和条目限制的处理,然后文章内容页面的翻页以及文章标题的处理,最后介绍了本地上传和 Google Cloud 云端 Shell 上传两种上传 KindleEar 项目的方式。
一、文章列表的翻页和限定条目
通常我们并不需要抓取网站上的所有文章条目,所以要从“文章数量”或“时间范围”这两种纬度限定文章条目。设定条件时,可选择其一,也可选取两者不同范围的交集。本例采用的是后者:先设定抓取 40 篇文章,再在此基础上保留 1 天之内的文章。由于设定值超过了单页文章数量,还需要处理列表翻页。
以下代码根据以上需求做了修改。从中可以看到,在之前代码的基础上,新导入了一个处理时间的模块,并新增了 2 个参数和 3 个自定义函数。下面我们来详细解释一下新增的这些代码都做了些什么。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from datetime import datetime # 导入时间处理模块datetime
from base import BaseFeedBook # 继承基类BaseFeedBook
from lib.urlopener import URLOpener # 导入请求URL获取页面内容的模块
from bs4 import BeautifulSoup # 导入BeautifulSoup处理模块
# 返回此脚本定义的类名
def getBook():
return ChinaDaily
# 继承基类BaseFeedBook
class ChinaDaily(BaseFeedBook):
# 设定生成电子书的元数据
title = u'China Daily' # 设定标题
__author__ = u'China Daily' # 设定作者
description = u'Chinadaily.com.cn is the largest English portal in China. ' # 设定简介
language = 'en' # 设定语言
coverfile = 'cv_chinadaily.jpg' # 设定封面图片
mastheadfile = 'mh_chinadaily.gif' # 设定标头图片
# 指定要提取的包含文章列表的主题页面链接
# 每个主题是包含主题名和主题页面链接的元组
feeds = [
(u'National affairs', 'http://www.chinadaily.com.cn/china/governmentandpolicy'),
(u'Society', 'http://www.chinadaily.com.cn/china/society'),
]
page_encoding = 'utf-8' # 设定待抓取页面的页面编码
fulltext_by_readability = False # 设定手动解析网页
# 设定内容页需要保留的标签
keep_only_tags = [
dict(name='span', class_='info_l'),
dict(name='div', id='Content'),
]
max_articles_per_feed = 40 # 设定每个主题下要最多可抓取的文章数量
oldest_article = 1 # 设定文章的时间范围。小于等于365则单位为天,否则单位为秒,0为不限制。
# 提取每个主题页面下所有文章URL
def ParseFeedUrls(self):
urls = [] # 定义一个空的列表用来存放文章元组
# 循环处理fees中两个主题页面
for feed in self.feeds:
# 分别获取元组中主题的名称和链接
topic, url = feed[0], feed[1]
# 把抽取每个主题页面文章链接的任务交给自定义函数ParsePageContent()
self.ParsePageContent(topic, url, urls, count=0)
print urls
exit(0)
# 返回提取到的所有文章列表
return urls
# 该自定义函数负责单个主题下所有文章链接的抽取,如有翻页则继续处理下一页
def ParsePageContent(self, topic, url, urls, count):
# 请求主题页面链接并获取其内容
result = self.GetResponseContent(url)
# 如果请求成功,并且页面内容不为空
if result.status_code == 200 and result.content:
# 将页面内容转换成BeatifulSoup对象
soup = BeautifulSoup(result.content, 'lxml')
# 找出当前页面文章列表中所有文章条目
items = soup.find_all(name='span', class_='tw3_01_2_t')
# 循环处理每个文章条目
for item in items:
title = item.a.string # 获取文章标题
link = item.a.get('href') # 获取文章链接
link = BaseFeedBook.urljoin(url, link) # 合成文章链接
count += 1 # 统计当前已处理的文章条目
# 如果处理的文章条目超过了设定数量则中止抽取
if count > self.max_articles_per_feed:
break
# 如果文章发布日期超出了设定范围则忽略不处理
if self.OutTimeRange(item):
continue
# 将符合设定文章数量和时间范围的文章信息作为元组加入列表
urls.append((topic, title, link, None))
# 如果主题页面有下一页,且已处理的文章条目未超过设定数量,则继续抓取下一页
next = soup.find(name='a', string='Next')
if next and count < self.max_articles_per_feed:
url = BaseFeedBook.urljoin(url, next.get('href'))
self.ParsePageContent(topic, url, urls, count)
# 如果请求失败则打印在日志输出中
else:
self.log.warn('Fetch article failed(%s):%s' % \
(URLOpener.CodeMap(result.status_code), url))
# 此函数负责判断文章是否超出指定时间范围,是返回 True,否则返回False
def OutTimeRange(self, item):
current = datetime.utcnow() # 获取当前时间
updated = item.find(name='b').string # 获取文章的发布时间
# 如果设定了时间范围,并且获取到了文章发布时间
if self.oldest_article > 0 and updated:
# 将文章发布时间字符串转换成日期对象
updated = datetime.strptime(updated, '%Y-%m-%d %H:%M')
delta = current - updated # 当前时间减去文章发布时间
# 将设定的时间范围转换成秒,小于等于365则单位为天,否则则单位为秒
if self.oldest_article > 365:
threshold = self.oldest_article # 以秒为单位的直接使用秒
else:
threshold = 86400 * self.oldest_article # 以天为单位的转换为秒
# 如果文章发布时间超出设定时间范围返回True
if (threshold < delta.days * 86400 + delta.seconds):
return True
# 如果设定时间范围为0,文章没超出设定时间范围(或没有发布时间),则返回False
return False
# 此自定义函数负责请求传给它的链接并返回响应内容
def GetResponseContent(self, url):
opener = URLOpener(self.host, timeout=self.timeout, headers=self.extra_header)
return opener.open(url)首先我们从 Python 标准库中导入了一个时间处理模块 datetime,这在验证文章时间范围时需要用到。
然后新增了 max_articles_per_feed 和 oldest_article 两个参数,前者用来设定从每个主题抓取的文章数量,后者则是用来设定要保留多久时间之内更新的文章。这两个参数的值都是数字。设置文章的时间范围时需要注意:如果设定的数值小于等于 365 单位是天,否则单位为秒,0 表示不限制时间范围。
最后添加了三个自定义函数,分别是 ParsePageContent()、OutTimeRange() 和 GetResponseContent()。其中函数 ParsePageContent() 的逻辑是从之前的 ParseFeedUrls() 函数中拆出来再被其调用的,为的是递归处理列表翻页,里面还新增了对文章数量和发布时间的判断,以便按照设定条件过滤文章。
根据翻页链接的 HTML 标签结构,代码中通过查找含有 Next 字符的 a 标签来确定当前列表是否有下一页,如果有的话就继续调用 ParsePageContent() 提取下一页内容,直到达到设定的抓取数量为止。
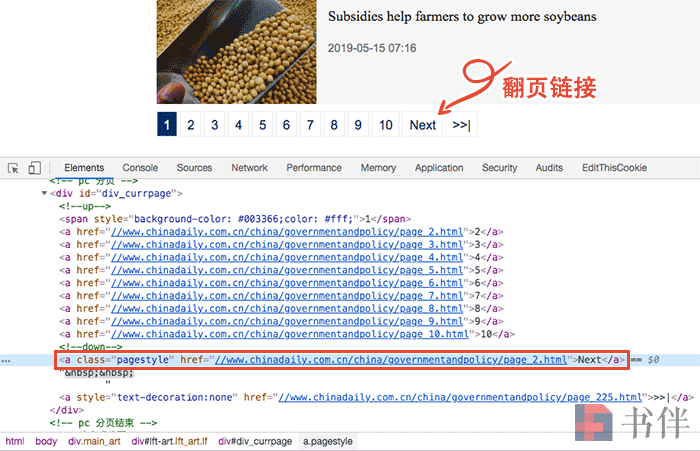
▲ 翻页链接显示效果和标签结构

▲ 翻页链接结构说明
其它两个函数的功能比较简单:OutTimeRange() 用来判断传入文章的发布时间是否超出了设定范围,然后把结果返回给调用函数使用;GetResponseContent() 用来请求传入的页面链接,然后把响应内容返回给调用它的函数,这主要是为了方便之后复用,因为下面处理文章内容翻页时也需要请求页面内容。
二、文章内容的翻页和细节修改
处理完文章列表的翻页,我们再来处理内容的一些细节:内容页的翻页和移除内容标题上的冗余信息。
下面是完善后的代码,也是本文最终完成的代码。新增的代码主要调用了基类中的 processtitle() 和 preprocess() 两个函数对文章内容做预处理,前者用来处理文章标题,后者用来处理文章内容。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from datetime import datetime # 导入时间处理模块datetime
from base import BaseFeedBook # 继承基类BaseFeedBook
from lib.urlopener import URLOpener # 导入请求URL获取页面内容的模块
from bs4 import BeautifulSoup # 导入BeautifulSoup处理模块
# 返回此脚本定义的类名
def getBook():
return ChinaDaily
# 继承基类BaseFeedBook
class ChinaDaily(BaseFeedBook):
# 设定生成电子书的元数据
title = u'China Daily' # 设定标题
__author__ = u'China Daily' # 设定作者
description = u'Chinadaily.com.cn is the largest English portal in China. ' # 设定简介
language = 'en' # 设定语言
coverfile = 'cv_chinadaily.jpg' # 设定封面图片
mastheadfile = 'mh_chinadaily.gif' # 设定标头图片
# 指定要提取的包含文章列表的主题页面链接
# 每个主题是包含主题名和主题页面链接的元组
feeds = [
(u'National affairs', 'http://www.chinadaily.com.cn/china/governmentandpolicy'),
(u'Society', 'http://www.chinadaily.com.cn/china/society'),
]
page_encoding = 'utf-8' # 设定待抓取页面的页面编码
fulltext_by_readability = False # 设定手动解析网页
# 设定内容页需要保留的标签
keep_only_tags = [
dict(name='span', class_='info_l'),
dict(name='div', id='Content'),
]
max_articles_per_feed = 40 # 设定每个主题下要最多可抓取的文章数量
oldest_article = 1 # 设定文章的时间范围。小于等于365则单位为天,否则单位为秒,0为不限制。
# 提取每个主题页面下所有文章URL
def ParseFeedUrls(self):
urls = [] # 定义一个空的列表用来存放文章元组
# 循环处理fees中两个主题页面
for feed in self.feeds:
# 分别获取元组中主题的名称和链接
topic, url = feed[0], feed[1]
# 把抽取每个主题页面文章链接的任务交给自定义函数ParsePageContent()
self.ParsePageContent(topic, url, urls, count=0)
# print urls
# exit(0)
# 返回提取到的所有文章列表
return urls
# 该自定义函数负责单个主题下所有文章链接的抽取,如有翻页则继续处理下一页
def ParsePageContent(self, topic, url, urls, count):
# 请求主题页面链接并获取其内容
result = self.GetResponseContent(url)
# 如果请求成功,并且页面内容不为空
if result.status_code == 200 and result.content:
# 将页面内容转换成BeatifulSoup对象
soup = BeautifulSoup(result.content, 'lxml')
# 找出当前页面文章列表中所有文章条目
items = soup.find_all(name='span', class_='tw3_01_2_t')
# 循环处理每个文章条目
for item in items:
title = item.a.string # 获取文章标题
link = item.a.get('href') # 获取文章链接
link = BaseFeedBook.urljoin(url, link) # 合成文章链接
count += 1 # 统计当前已处理的文章条目
# 如果处理的文章条目超过了设定数量则中止抽取
if count > self.max_articles_per_feed:
break
# 如果文章发布日期超出了设定范围则忽略不处理
if self.OutTimeRange(item):
continue
# 将符合设定文章数量和时间范围的文章信息作为元组加入列表
urls.append((topic, title, link, None))
# 如果主题页面有下一页,且已处理的文章条目未超过设定数量,则继续抓取下一页
next = soup.find(name='a', string='Next')
if next and count < self.max_articles_per_feed:
url = BaseFeedBook.urljoin(url, next.get('href'))
self.ParsePageContent(topic, url, urls, count)
# 如果请求失败则打印在日志输出中
else:
self.log.warn('Fetch article failed(%s):%s' % \
(URLOpener.CodeMap(result.status_code), url))
# 此函数负责判断文章是否超出指定时间范围,是返回 True,否则返回False
def OutTimeRange(self, item):
current = datetime.utcnow() # 获取当前时间
updated = item.find(name='b').string # 获取文章的发布时间
# 如果设定了时间范围,并且获取到了文章发布时间
if self.oldest_article > 0 and updated:
# 将文章发布时间字符串转换成日期对象
updated = datetime.strptime(updated, '%Y-%m-%d %H:%M')
delta = current - updated # 当前时间减去文章发布时间
# 将设定的时间范围转换成秒,小于等于365则单位为天,否则则单位为秒
if self.oldest_article > 365:
threshold = self.oldest_article # 以秒为单位的直接使用秒
else:
threshold = 86400 * self.oldest_article # 以天为单位的转换为秒
# 如果文章发布时间超出设定时间范围返回True
if (threshold < delta.days * 86400 + delta.seconds):
return True
# 如果设定时间范围为0,文章没超出设定时间范围(或没有发布时间),则返回False
return False
# 清理文章URL附带字符
def processtitle(self, title):
return title.replace(u' - Chinadaily.com.cn', '')
# 在文章内容被正式处理前做一些预处理
def preprocess(self, content):
# 将页面内容转换成BeatifulSoup对象
soup = BeautifulSoup(content, 'lxml')
# 调用处理内容分页的自定义函数SplitJointPagination()
content = self.SplitJointPagination(soup)
# 返回预处理完成的内容
return unicode(content)
# 此函数负责处理文章内容页面的翻页
def SplitJointPagination(self, soup):
# 如果文章内容有下一页则继续抓取下一页
next = soup.find(name='a', string='Next')
if next:
# 含文章正文的标签
tag = dict(name='div', id='Content')
# 获取下一页的内容
result = self.GetResponseContent(next.get('href'))
post = BeautifulSoup(result.content, 'lxml')
# 将之前的内容合并到当前页面
soup = BeautifulSoup(unicode(soup.find(**tag)), 'html.parser')
soup.contents[0].unwrap()
post.find(**tag).append(soup)
# 继续处理下一页
return self.SplitJointPagination(post)
# 如果有翻页,返回拼接的内容,否则直接返回传入的内容
return soup
# 此自定义函数负责请求传给它的链接并返回响应内容
def GetResponseContent(self, url):
opener = URLOpener(self.host, timeout=self.timeout, headers=self.extra_header)
return opener.open(url)函数 Items() 抓取文章内容时,是从页面 <title> 标签中获取文章标题的,但是 China Daily 的文章标题都附加了一个重复的尾巴,类似 XXXXX - Chinadaily.com.cn,所以我们需要调用一个现成的预处理函数 processtitle() 把这个尾巴删掉,在函数中我们只需要简单地用 replace() 函数将其替换为空即可。
在函数 readability_by_soup() 清洗页面内容前,我们可以调用另一个现成的预处理函数 preprocess() 对原始的页面内容做些处理,在这里我们就是通过调用此函数来处理含内容页面翻页的。在本例中,含翻页的文章页面虽然不常见,但确实存在,比如“China, Thailand conclude joint naval training”这篇文章,四幅图片被放进了四页,如果不对其做相应处理,推送后就只能看到这篇文章的第一张图片。
自定义函数 SplitJointPagination() 用来递归处理文章页面的翻页。当此函数被 preprocess() 调用时,会查找传入的页面是否有下一页,如果有就读取下一页内容,直至把所有翻页内容拼接在一起返回。
至此就完成了为 China Daily 网站定制的订阅脚本。因为该网站所有板块的 HTML 标签结构几乎是相同的,所以你可以在 feeds 参数中增加你喜欢的其它主题页面链接。不过要注意,Google App Engine 对资源的使用有限制,而且 Gmail 发信对附件的推送也有 20MB 的限制,不建议一次性抓取过多内容。
三、上传到 Google App Engine
订阅脚本编写完成之后就可以上传到正式的 Google App Engine(GAE)环境上使用了。如果你想要在本地上传,可参照《KindleEar 搭建教程:推送 RSS 订阅到 Kindle》这篇文章提供的“手动上传”步骤操作。当然也可以采用另一种方式,即先把修改的源码 Push 到 Github,再用 GAE 的云端 Shell 上传。
通过云端 Shell 上传,如果你身在中国大陆,需要通代理上网访问 Google Cloud 服务。
上传 KindleEar 源码前,建议检查项目文件 config.py 中的 SRC_EMAIL 和 DOMAIN 这两个参数,确保都已经改成了你自己账号的相关信息。在本地测试推送时,本文示例曾修改过文件 config.py 中的 SRC_EMAIL 这个参数,上传前务必要改回你的 Gmail 邮箱,否则会导致 KindleEar 应用推送失败。
从 Github 拉取源码上传过程比较简单。确保你修改的 KindleEar 源代码已成功 Push 到 Github,然后进入 Google App Engine 控制台,点击右上角的“Shell 图标”激活云端 Shell,依次执行如下命令上传:
git clone https://github.com/YOURNANME/KindleEar.git
cd KindleEar
gcloud app deploy *.yaml --version=1 --quiet上传成功就可以登录 KindleEar 添加和推送新订阅了。如果新添加的订阅没出现,就表示没上传成功,建议仔细检查自己的操作步骤(可根据终端或命令提示符上出现的错误提示排查上传失败的原因)。


▲ 订阅脚本最终推送效果
如果你对本教程有什么疑问,或者发现内容存在谬误或不详尽之处,欢迎留言。
© 「书伴」原创文章,转载请注明出处及原文链接:https://bookfere.com/post/753.html
“Kindle推送”相关阅读
- Send to Kindle 微信推送教程:用 Kindle 读长文
- 中亚微信推送服务 Send to Kindle 全新升级
- KindleEar 搭建教程:推送 RSS 订阅到 Kindle
- EpubPress:把打开的多个网页转成一本电子书
- 新手 3 分钟 GET!视频版 Kindle 推送教程
- 外出旅行时如何用安卓手机推送电子书到 Kindle
- 如何快速无损修复推送失败的 EPUB 格式电子书文件
- 如何利用 Sigil 和 EpubCheck 插件检查和修复 EPUB 文件
- 亚马逊 Kindle 个人文档服务已原生支持推送 EPUB 格式
- 利用 IFTTT 自动推送上传到 Dropbox 的电子书
- Kindle 怎么导入电子书(图解多种电子书导入方式)
- 通过 Send to Kindle 发送的文档已支持 KFX 增强排版功能
- 如何直接推送 EPUB 格式电子书到 Kindle 邮箱
- Kindle 退出中国后如何继续购买电子书及使用推送服务
- 解决 Calibre 推送“500 Error: bad syntax”错误
应该是信用卡过期了,更新日期后又可以继续用了
4月9号又出现 500 Server Error是什么情况呢?已经绑定银行卡了
Error: Server Error
The server encountered an error and could not complete your request.
Please try again in 30 seconds
上传到 Google App Engine那部分是近期要重写吗?今天想试试这个教程来着
将 KindleEar 部署到 GAE 的步骤已经全部重写。
我对脚本做了改动要重新上传,执行命令git clone https://github.com/***/**.git后,提示fatal: destination path ** already exists and is not an empty directory.
执行 rm -rf **也不行
执行 clone 命令时,当前目录确实不为空吗?用 ls 查看一下。
显示有个README-cloudshell.txt,用命令rm -i README-cloudshell.txt删除就可以了,不知道rm -rf怎么不行。谢谢!
为啥我的KindleEar源码文件太多,push不到GitHub
具体是什么提示?
谢谢回复,我搞懂了,我刚开始不会用Github。
1.我还想知道,所有的网站都可以用这个模板吗?用的时候主要是改哪些东西啊,身为小白,里面的程序理解起来太艰难了。
2.还有是不是每添加一个类似于Chinadaily.py的源,都得再把所有的文件重新上传到Google shell。
1、对于没有完全没有编程基础的小伙伴来说,确实需要掌握一定的基础知识才行,一两句话说不清楚。等研究一下,看能不能实现用通用模板解决这个问题。2、是的,对源码做了改动(如添加一个 py 订阅脚本)就需要上传一次。
请问本地调试系统生成的mobi书,推到kindle邮箱后,在阅读器上打开正常;为何把写好的py文件传到GAE上后,推送到kindle上的mobi书打不开,提示打开错误让删除呢?
有时候 Kindle 系统会莫名其妙的出现这种问题,建议先重启一下 Kindle 试试。
我之前按照KindleEar搭建教程成功搭建,现在我也已经编辑好订阅源,并上传到Github,现在在云端输入git那行命令,但是提示我错误,fatl:destination path ‘KindleEar’ already exists and is not an empty directory。请问是什么原因,
使用 Git 命令拉取源码前,先用命令
rm -rf KindleEar把已存在的 KindleEar 文件夹删掉。你好,之后输入appcfg.py update ./app.yaml ./module-worker.yaml,提示appcfg.py: error: Error parsing ./app.yaml:mapping values are not allowed here in “./app.yam”. line2, column 8.这要怎么解决?
你修改的 app.yaml 有错误,在第二行。你需要自己仔细检查一下,尤其注意冒号后面要留空格。
非常感谢,成功了
佩服的五体投地!