
[网友投稿] 用 WebToEpub 将在线电子书转换成 EPUB 文件
![[网友投稿] 用 WebToEpub 将在线电子书转换成 EPUB 文件](https://bookfere.com/wp-content/uploads/2022/05/gitbook-convert-to-epub.png)
本文系网友 Jason Huang 的投稿,节选自其分享的长文《手机配合Kindle如何看书、网文、论坛连载和稍后读》。内容在保持原意的基础上,按照书伴的文章发布需要做了修整。
很多书籍有在线电子书,但是一时找不到离线的电子书文件,想用 Kindle 的浏览器阅读,体验也十分糟糕。同理,一些论坛连载的文章、小说等,在 Kindle 上的阅读体验也不理想。
我们可以用 WebToEpub 这款插件将这些在线内容转换成 EPUB 文件推送到 Kindle,来实现离线阅读这些电子书和论坛连载,该插件支持 Chrome 和 Firefox 浏览器,可通过以下链接安装:
- 下载安装 WebToEpub 插件:离线安装包 | Chrome 在线安装 | Firefox 在线安装
GitBook 上有很多好书,但是没有提供 EPUB 版本,甚至没有离线版本。下面就以 GitBook 为例介绍一下如何将在线电子书《Spring 实战(第 6 版)》转制成 EPUB 格式离线电子书文件。
首先用浏览器访问:http://www.cyxhxh.ltd/books/spring-in-action-v6/index.html
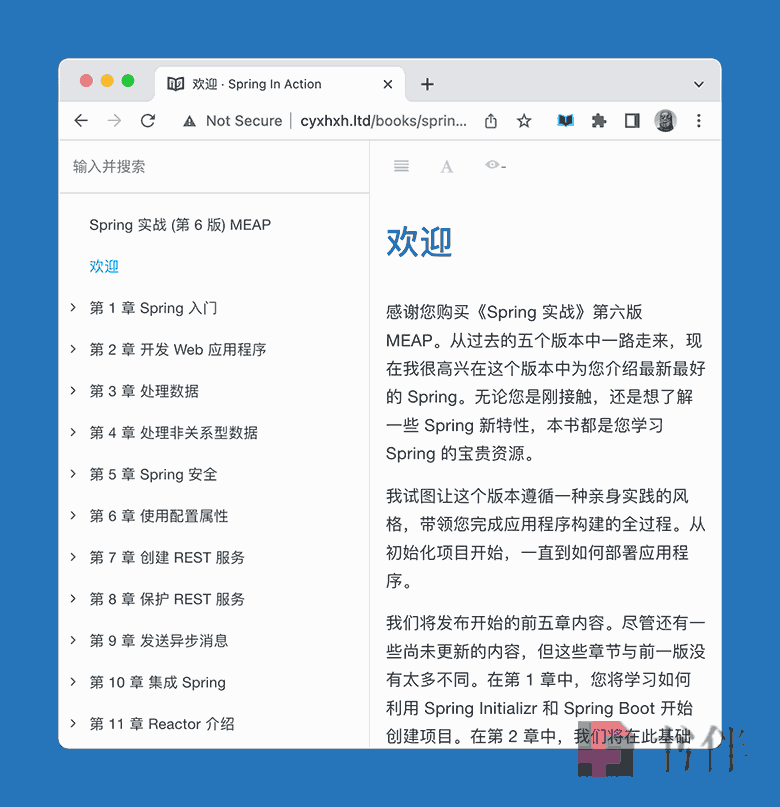
打开网址可看到如上图所示的页面,点击 WebToEpub 插件图标,会出现如下所示界面:
为了让 WebToEpub 准确地抓取我们所需要的内容,需要填写如下所示的几个设置项:
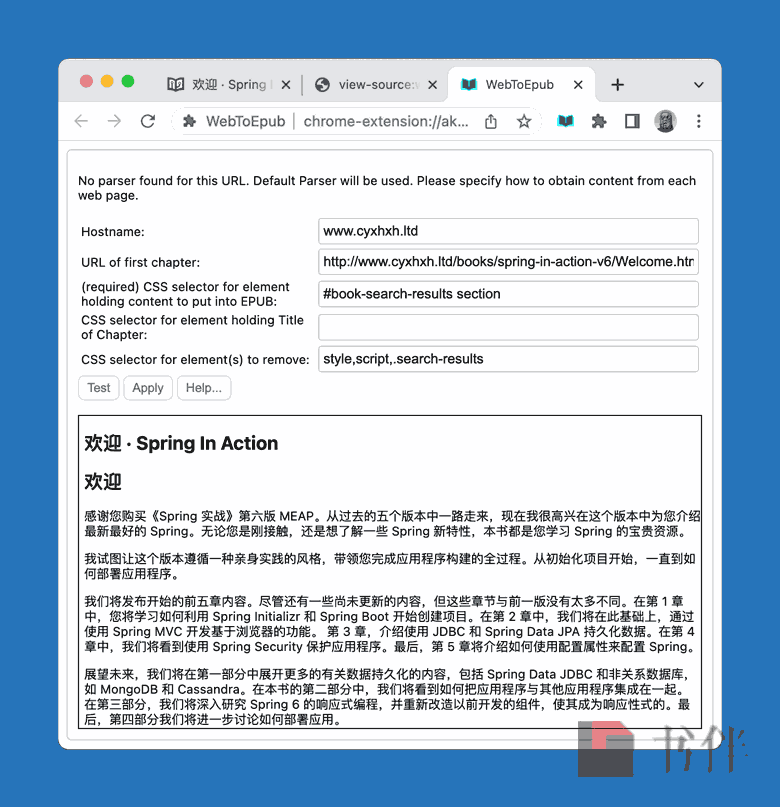
下面来详细解释一下这几个设置项具体是什么含义:
- URL of first chapter:首个章节页面网址
- CSS selector for element holding content to put into EPUB:内容所在元素的 CSS 选择器
- CSS selector for element holding Title of Chapter:章节标题所在元素的 CSS 选择器
- CSS selector for element(s) to remove:要移除元素的 CSS 选择器
首先需要让 WebToEpub 知道从哪个网址开始抓取内容,这里可以选择任意包含章节目录的网址,比如使用首页网址,就可以在【URL of first chapter】的输入框中填入如下所示网址。
http://www.cyxhxh.ltd/books/spring-in-action-v6/index.html默认情况下,WebToEpub 会抓取整个网页,即 <body> 元素中的所有内容,为了让 WebToEpub 知道从哪个元素中获取书中每个章节的正文内容,需要为其指定确切的 CSS 选择器。可以右键点击网页,选择【检查】调出开发者工具,通过检查 HTML 元素功能(或选择【显示网页源代码】,通过查看 HTML 源代码),找到文章正文内容所在的 HTML 元素。
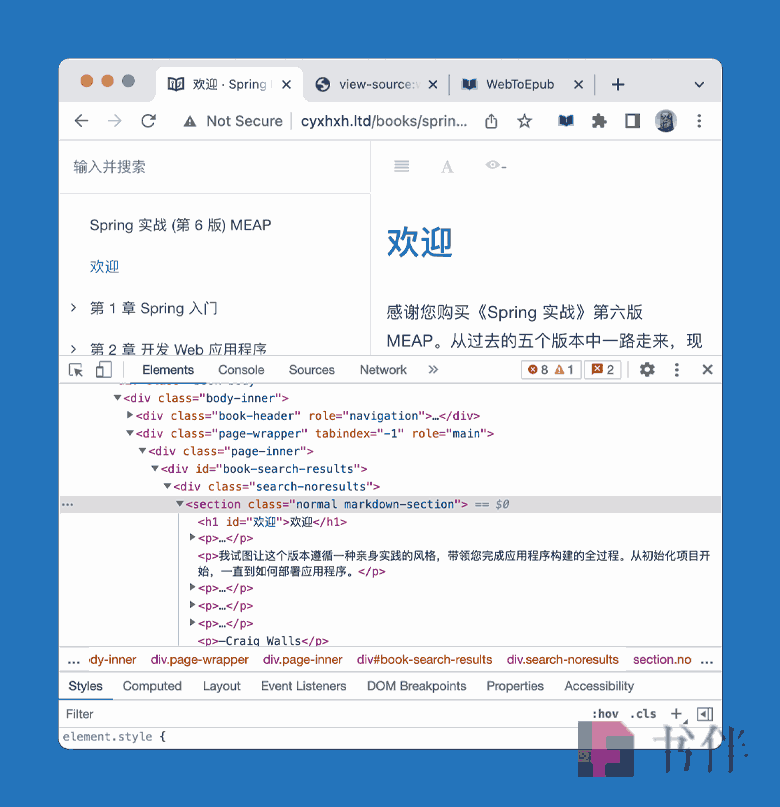
通过检查,可以看到页面的正文内容是在 <section> 元素中,因此可以在【CSS selector for element holding content to put into EPUB】输入框中填入将该元素的标签名 section。为确保 CSS 选择器的唯一性,可以使用合适的后代选择器,如 #book-search-results section。
同理,可以为章节内容添加章节标题,可以在【CSS selector for element holding Title of Chapter】输入框中填写文档标题元素的标签名 <title> 或 标题元素的标签名 <h1>。注意,如果正文中包含了本章的标题,这一项就不要填写了,免得生成的电子书有两个标题。
对于一些页面,可能会存在很多生成电子书所不需要的内容,包括 <style>、<script> 等元素以及其它与内容不相关的 HTML 元素。因此我们可以在【CSS selector for element(s) to remove】中填写这些元素的 CSS 选择器,让插件提取内容时排除指定元素中的内容。
必要的设置项填写完成后,点击【Test】按钮即可预览首个章节的内容抓取情况。如果内容抓取有误,比如内容有缺失,或有不需要的额外内容,适当调整上面提到的 CSS 选择器。
如果一切无误点击【Apply】按钮,进入 EPUB 文件设置界面,定制要生成的 EPUB 电子书。
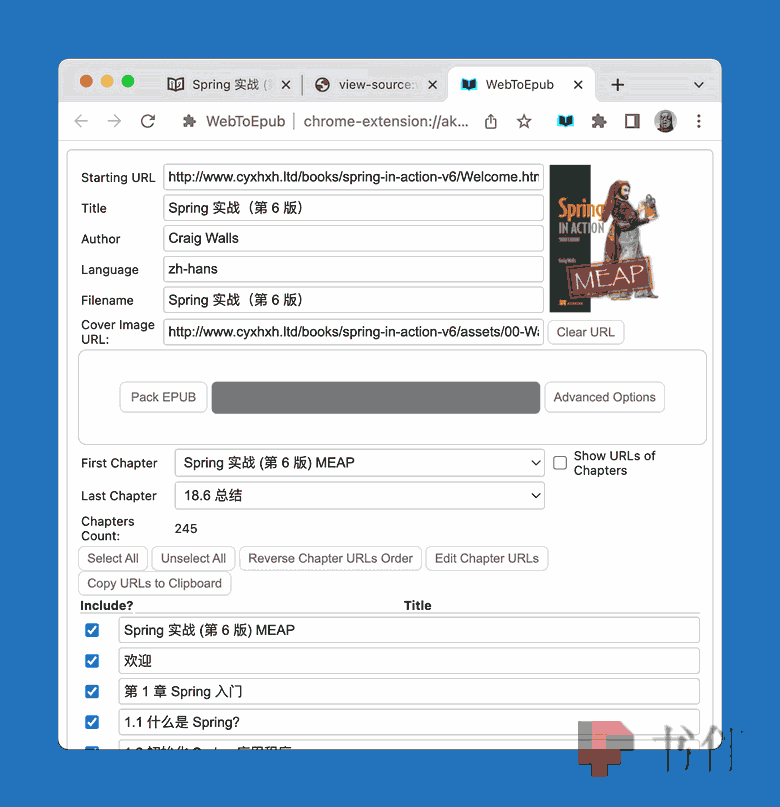
首先要填写元数据。包括书名、作者、封面图片 URL 等,这会让生成的电子书会更完美。
然后是选择让插件抓取的章节。你可以通过单个勾选复选框(或按 Shift 键多选)的方式保留或排除要抓取的章节,也可以通过【First Charter】和【Last Chapter】选择第一个章节和最后一个章节的标题,让插件自动勾选两者及两者之间的所有章节。
论坛的帖子常采用从新到旧的排序方式,你可以点击【Reverse Chapter URLs Order】按钮重新排序一下,让旧章节在前,这样更符合阅读习惯。另外,还可以点击【Advanced Options】做一些更细颗粒度的控制,例如修改电子书的 CSS 代码让排版更符合自己阅读习惯,或者让插件仅抓取文本而排除图片等。不过一般情况下不用调整这些选项。
设置完毕即可点击【Pack EPUB】按钮,让插件抓取页面内容并将其打包成 EPUB 文件。插件抓取并打包完毕后,会弹出保存对话框,选择要保存的路径,即可得到最终的 EPUB 电子书文件。

最后,将生成的 EPUB 电子书文件通过邮箱推送到 Kindle(如何推送?),就可以阅读了。

只要源页面的 HTML 结构良好,推送到 Kindle 后的阅读体验都还不错。
© 「书伴」原创文章,转载请注明出处及原文链接:https://bookfere.com/post/975.html
试了一下,没法抓取多层目录结构的网站,只能一层
这个是没法抓取微信公众号文章吗?还是我的操作问题?
可以试试 Send to Kindle 或 EpubPress 这两款 Chrome 插件。
好像浏览器开发者工具里有的会自带复制selector工具 ,移到对应的元素代码上,看网页上被锁定的是该元素,右键-复制-复制selector,就会自动生成对应的元素路径到剪贴板,比如我要移除的一个元素
#page-content > div
使用的是基于Chromium的Edge浏览器
有时候得到的章节是错误的, 不是想要的, 不知道是我的问题还是插件的局限, 比如https://www.jetbrains.com/help/clion/analyzing-applications.html?keymap=secondary_macos的说明文档
从这个插件项目的 README 中列出的适用网站来看,应该是插件自身的局限。估计处理简单点的目录结构以及有针对性支持的网站没啥问题,而结构稍微复杂点的可能就不太好用了。
还是喜欢用sigil制(修)作(改)epub
Sigil能抓取在线网页制作电子书吗?